





文摘
过早表现型COVID-19患者,我们和我们的患者严重,预防风险。如果数据驱动的表型不坚持,我们的认知偏见保证我们将最终phenotype-driven数据。https://bit.ly/2ZM8wZV
严重急性呼吸系统综合症冠状病毒2带来了前所未有的全球卫生挑战。严重的冠状病毒疾病2019 (COVID-19)肺炎常常导致hypoxaemic呼吸衰竭,展现在急性呼吸窘迫综合征(ARDS)。最近,作者提出了不同的临床表型COVID-19肺炎在几个有影响力的、引人注目的文章(1- - - - - -3]。例如,在最近的观点在这个杂志(3),作者推测COVID-19有五个表型演示:三个表型基于低血氧症的严重程度和需要支持性护理(没有低氧血,轻度低氧血和中度低氧血),和两个表型严重hypoxaemic患者基于额外的生理和临床特征。与近期其他努力表型COVID-19患者(1,2),作者子类型患者到所谓普遍表型正常合规,低肺重量,和主要灌注异常(“L”表型),和一个弱的表型与ARDS的典型特征,如深刻的整合和低合规(“H”表型)。作者提倡为这些所谓的表型不同的管理策略,包括允许增加潮汐卷和限制在“L”呼气末正压通气的表型患者。
表型的冲动COVID-19患者肺炎是可以理解和产生共鸣。在危重病医学之外,过去十年一直以精密医学的重大进展,基于个人前途的个体化治疗病人的生理和生物学特性。小说的出现疾病没有有效治疗激励heuristic-based识别子集的病人可能反应类似于一个特定的干预。然而这诱惑表型定义基于早期临床经验应该抵制。过早表现型的病人,我们风险造成相当大的伤害和生成静态多信号。在这篇社论中,我们提供了四个反对过早表现型,讨论负责任的表型出现的特点,以及推荐的路径向前推进我们的理解真正的异质性底层COVID-19患者(图1)。
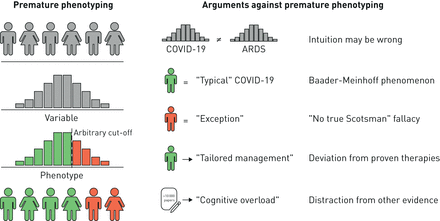
过早表现型的危险。通过专注于极端的一个正态分布的连续体,我们风险创建任意的“表现型”不代表有意义的潜在病理生理学上的差异。过早表现型通常是基于错误的初始印象和导致认知偏差,包括Baader-Meinhoff现象(“频率偏差”)和“没有真正的苏格兰人”谬论(不含不兼容的观察通过一个特别的纯度测试)。过早表现型可以妥协的交付由激励偏离循证护理实践,以及造成不必要的临床医生的认知负荷。
第一,简单,反对过早表现型是我们最初的直觉往往是错误的。作为一个生动的例子,一位著名的文章(2)最近宣称没有资格,”从COVID-19很快出现呼吸窘迫,患者最初保持相对良好的合规尽管非常贫穷的氧化。”这一说法,而不支持的参考引用,形成扩展的基础讨论患者的病理生理学和定制管理这个传说中的“L表型”COVID-19(如上所述)。然而随后的队列研究表明肺合规COVID-19患者实际上是相当低(4,5),完全等同于non-COVID-19 ARDS军团(6- - - - - -8),和正态分布连续,而不是现有的离散表型。此外,传说中的射线这些表型和生理特性(如。密集的空域填充在计算机断层扫描与减少合规“H”表型)后来被证明是完全彼此不相关的(9]。识别的临床表型,关于他们的基本生物学和猜测,应该推迟到以后小心,充分的客观检查大小的军团。人类的直觉太不可靠的,临床经验太偶然和异构,可靠地确定表型没有足够的数据。
一个相关的反对过早表现型是加剧了我们内在的易感性认知偏见。一旦我们了解临床类别(然而假他们可能),我们的大脑对待他们一样真实,并开始有选择地过滤我们的观察。作为一个例子,在传播since-disproven声称COVID-19患者保留肺合规,神话是强化了共同的认知陷阱。“巴德尔•迈因霍夫现象(也称为“频率错觉”)保证一旦临床医生提示注意COVID-19接近于正常的肺患者依从性,他们开始注意到到处都是(而事实上他们的频率没有高于non-COVID ARDS) (6- - - - - -8]。同样,临床医生可以把low-compliance COVID-19病例在无意中犯了“没有真正的苏格兰人”谬论:通过解雇声称在一个异常特别的基础,声称low-compliance COVID-19必须典型情况下,随着“真实”COVID-19接近于正常的呼吸力学。如果我们不坚持数据驱动的表型,认知偏见保证我们将与phenotype-driven最终数据。
第三个反对过早表现型是它干扰了我们的声音,以证据为基础的做法。临床结果在ARDS近几十年来有了显著的进步10畅销药),而不是发现,而是由改进的支持性护理。这些缓慢但不断进步是建立在来之不易的教训严格的随机对照试验。通过他们的设计,这些试验异构ARDS患者“集中”在一起syndrome-based下定义。尽管如此,这些试验领域提供了一个广泛的文献通知证据支持疗法。擅自分裂COVID-19病人到错误的表型,通过推荐基于未经考验的生理直觉“定制管理”,作者主张放弃剩下的我们最有效的工具对COVID-19:细致、证据驱动关键的保健服务。
最后一个反对过早表现型是它加剧了ICU already-unfavourable信号和噪音的比率。在床边,重症监护医师必须过滤,处理和解释一个巨大的流数据生成的每一个病人:生理、生化、射线照相,等。临床医生必须合成这些发现与出版的文献,也同样令人生畏:超过10 000 PubMed-indexed手稿COVID-19发表在2020年的前4个月。这海量的信息威胁最被忽视和ICU的宝贵的资源:临床医师的关注,时间和带宽。不必要的情况不明朗的临床,假表型消耗时间轮,使我们远离更加迫在眉睫的问题。同样作为一个领域,我们的研究优先级已经蒙上了阴影:调查人员的时间和资源浪费试图解释生物学基础的临床现象,检查病人数据,根本不存在。
负责任的表现型看起来像什么?与任何科学实验一样,需要有一个明确的目的,为什么我们寻求表型(表1)。在医学科学,这个要求最终收敛于改善患者的结果得到新颖的生物和临床(尽管见解是一个同样重要的激励因素,因为他们可能实现这一目标的关键)。为此,我们最近的例子的经验领域已成功地用于识别treatment-responsive表型和/或生物不同的子组。在哮喘中,例如,使用数据驱动的无偏见的聚类方法,两种截然不同的表型哮喘被确定基于interleukin-13诱导的基因表达(11]。表型特征具体高基因表达后来表明,随机对照试验,能够响应单克隆抗体抑制interleukin-13活动(12]。在ARDS,再次使用无偏聚类方法,两个表型与不同的生物和临床特点,已确定一致的横跨5个随机对照试验和临床结果明显不同(13]。重要的是,三个随机对照试验中,不同的治疗反应观察随机干预措施。进一步、更简单的模型描述最近提供的潜在临床应用这些表型(14]。
这些数据驱动方法聚类并不是不受错误和滥用。这些都是强大的工具,独立研究问题的有效性或研究设计,集群将不可避免地出现。因此,调查人员义不容辞的演示确定表型的有效性和实用性。在缺乏地面真理,有效性的最佳代理的条件是:1)健壮性、2)一致性和3)再现性外部数据从他们的人口。在几乎所有算法,确定的表型是高度的预测变量。在危重COVID-19病人作为一个具体的例子,必须承认,我们正在研究复杂生物系统的相互关联的途径分享非线性关联。寻求单变量的解决方案在这些人口,因此,似乎不太可能产生有意义的子组其他比预测15]。此外,单变量的解决方案,特别是当寻求过早,可以更容易的中心极限定理。这个数学定理指出,给定一个足够大的样本量,变量的分布方式将收敛于正态分布,表明连续变量与有限的数据出现双峰,随着时间的推移将正态分布。因此,无论是生物合理性和数学原理,我们不太可能获得有用的表型如果我们在简单的锚,一维特征的疾病。
为了避免这些缺陷,在多变量模型预测变量应该选择研究问题的思想和高度信息化的有效分离。此外,这些复杂的数据科学算法的使用,旨在克服认知偏差,理论将是有限的,除非他们都伴随着一个测量系统,可以快速且一致地确定表型。不管使用的动机和方法,表型出现在危重病通常用疯狂的运动,在研究目前声称COVID-19表型,遗憾的是缺乏必要的数量和质量的数据。最终,然而,真正的成功将判断疾病的表型鉴定的可行的干预措施。在急救护理,虽然很多异构治疗效果的例子在表型中描述的二次分析,其功效需要测试通过随机对照试验。仅仅识别疾病表型是否过早派生或负责任地,本身不应该改变临床实践,而是告诉未来,“phenotype-aware”试验。
总之,COVID-19大流行给临床医生和研究人员提出了新的挑战。当我们分享裁剪的终极目标治疗每个病人的具体病理生理学的条件,我们首先必须客观地收集、整理和解释足够数据综合理解疾病和“类型”。过早的表现型COVID-19患者,我们让我们自己和我们的病人相当大的和可预防的风险。
可共享的PDF
脚注
利益冲突:L.D.J. Bos报告从荷兰肺脏基金会赠款(青年科学家基金项目),荷兰肺脏基金会(公私合作资助),荷兰肺脏基金会(Dirkje Postma奖),个人费用从拜耳(咨询公司),在提交工作。
利益冲突:p . Sinha没有披露。
利益冲突:r。迪克森没有披露。
- 收到了2020年5月13日。
- 接受5月23日,2020年。
- 版权©2020人队
这个版本分布在创作共用署名非商业性许可证的条款4.0。











{kind=link}
{kind=link}