





文摘
新的、复杂的工具被用来增进我们的知识多环芳烃和促进基于表型的个性化治疗http://ow.ly/qP6h30ocllp
肺动脉高压(PAH)是一种罕见的肺血管疾病的特点是逐步改造和肺动脉的缩小由于病理异常的成纤维细胞,炎症细胞、内皮细胞和平滑肌细胞(1]。几十年的临床、平移和长椅上研究先进我们理解底层机制导致PAH的发展。然而,尽管相当大的异质性的疾病,目前的诊断和治疗指南仍然主要是标准化。除了军团与长期应对钙通道阻滞剂,个性化治疗方案针对不同表型的多环芳烃尚未确定。旨在发现疗法研究的努力目标疾病机制,包括遗传和表观遗传突变,改变新陈代谢、荷尔蒙信号,炎症和氧化应激2]。
正是在这种背景下,Cornetet al。(3]若有所思地寻求新方法,进一步理解病理生理学的多环芳烃。九事件情况下的多环芳烃被发现在法国肺动脉高压患者的注册中心在2006年和2010年之间接收达沙替尼,一个强有力的第二代蛋白激酶抑制剂(PKI),用于治疗慢性粒细胞性白血病。这些病例观察8到48个月后首次接触达沙替尼和与功能和血流动力学障碍的特点是严重多环芳烃。改进,但不是完全恢复,观察4个月内的达沙替尼停药(4]。在过去三年还有很多其他事件的报道多环芳烃或恶化的现有的多环芳烃与其他公钥基础设施,包括Src-family PKI(即bosutinib和ponatinib)和JAK1/2 PKI ruxolitinib [5,6]。
在他们的报告发表在这期的欧洲呼吸杂志Cornetet al。(3)使用世界卫生组织药物警戒数据库,Vigibase,确定22 pki与至少一种多环芳烃。药物警戒的实践中提取药物不良事件(面)自发报告系统来识别先前未被确认的上市后出去。Vigibase已经从个案收集数据安全报告自1968年以来,包含∼1600万报告疑似出去,来自150多个国家。
虽然没有黄金标准数据挖掘方法,自发报告系统,比例失调分析是一种常用的技术应用于计算潜在的期望比埃兹(7]。在这项研究中,五个22 pki与积极的比例失调有关信号:达沙替尼,bosutinib ponatinib, ruxolitinib nilotinib。识别药效学特性,进行系统的文献回顾和产生了关联数据的16个22 pki。关联数据随后与35蛋白激酶(PKs)参与PAH病理生理学。五PKI目标与比例失调的信号:四个Src激酶(c - Src, c-yes Lck,林恩)和侦探。最后,聚类分析进行确定的pki与PK关联数据描述每种药物的亲和力。有趣的是,达沙替尼的亲和形象不同于其他药物。这些发现与以前一致PKI-associated机械的数据和案例报告发表的多环芳烃和支持的潜在致病作用与其Src (8,9]。由于PKI-associated PAH的罕见事件,很可能unelucidated机制如遗传、表观遗传、炎症或环境因素导致疾病的发展。然而,本文研究结果突出一个激动人心的突破PKI-associated多环芳烃可能的机制。
也许更令人兴奋的是这部小说的方法这些研究者在分析现有资源,在这种情况下Vigibase,推进我们对多环芳烃异构疾病的理解。本文补充日益复杂的方法被多环芳烃研究表型和识别个性化目标在多环芳烃(图1)。例子包括通过Phenomics多中心肺血管疾病(PVDOMICS)研究中,目前正在进行,旨在利用深表现型与全面的“使”分析发现肺血管疾病的分子亚型,允许重新分类,开发有针对性的治疗方案,和个性化管理基于表型特征的多环芳烃(10]。
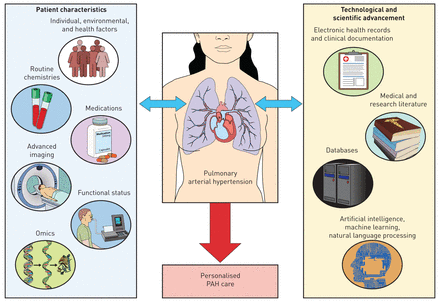
复杂的方法被用于表型和识别个性化目标肺动脉高血压(PAH)。
另一个例子是H的工作人物et al。(11描述转录和遗传差异,描述vasodilator-responsive PAH (VR-PAH)没有响应多环芳烃(VN-PAH)。转录组分析进行外周血白细胞发现13的25审问VR-PAH中差异表达的基因与VN-PAH,因此作为一个概念验证研究,基因表达差异中可以检测到血液和用来预测vaso-responsiveness。全外显子组测序随后进行36 PAH患者,这是映射到全基因组关联研究数据显示多个罕见的遗传变异,聚集在关键的生物通路与多环芳烃。VN-PAH相比,一个浓缩的基因参与血管平滑肌收缩是VR-PAH,表明遗传易感性vaso-responsiveness (12]。全外显子组测序也表现在儿科人口mutation-negative PAH情况下的n .朱和同事发现新创以新的基因变异可以解释∼paediatric-onset特发性PAH病例的19% (13,14]。
几乎普遍的医疗记录数字化,电子数据库的发展,扩大生物信息学和基因组研究领域,有一个个人健康指标的整合能力,增加与biorepositories分子数据和临床药理学研究15]。人工智能(AI),它使用技术,如机器学习(毫升)和自然语言处理(NLP),正在利用精密医学模拟人类思维过程来解决复杂的问题,提取、分析、和解释大量数据和非结构化文本转换成可用的数据16]。最近,年代weattet al。(17]应用毫升分析蛋白质组免疫的PAH患者外周血和发现四个不同免疫集群展示不同临床风险概况和结果独立于多环芳烃亚型,病人的人口统计,并发症或背景疗法。使用毫升工具和贝叶斯统计,正在努力重新分析揭示注册表数据以改进预测精度1年生存在PAH (18]。毫升也被用来创建computation-derived指标在磁共振成像(MRI)来提高MRI诊断准确性的PH值和预测生存模式的基础上右心室收缩期运动(19,20.]。拜耳和默克收到FDA突破设备名称2018年发展的人工智能软件来识别模式识别在慢性血栓栓塞肺动脉高压(CTEPH)。这种方法利用深度学习方法整合心脏,灌注与临床病史和肺血管信息支持放射科医生确定CTEPH [21]。计算机科学人工智能原理,毫升和NLP也越来越多的被应用到数据库,包括领域的药物警戒,从而增加了相关性这里介绍的工作。
几个挑战极限的使用药物警戒数据库在实时的研究中,包括有偏见、不完整或未报告事件和报告和确认面之间的显著的延迟。可以克服这些挑战将NLP算法纳入电子健康记录(EHR)数据库(7]。例如,通过提取结果信息从非结构化文本中包含的EHR,结合这与FDA不良事件报告系统(一个总部位于美国的自发报告系统)数据集,W盎et al。(22)最近演示了用NLP捕捉出去,而不是以前的可行性确定结构化电子健康档案数据。NLP算法应用到其他数据集,包括网络报告系统,实时识别和发表的文献,有潜力的面,否则会unanalysed (23]。应用NLP的力量和药物警戒监视EHR加强遗传信息整合时,作为这可能揭示个体遗传多态性改变药物代谢或使埃兹(24]。
连接电子健康档案数据通过人工智能与基因组学、ML NLP是一种宝贵的资源和巨大的潜力,可以扩大在多环芳烃的研究,进一步阐明疾病表型。尽管明显的病人人口挑战不可能反映了整个社区,不一致的数据收集内部和之间的电子医疗纪录,缺乏标准化的表现型的本体,和伦理和隐私问题,有许多优势,使用数据从电子医疗纪录中提取耦合生物银行。传统研究耗时和昂贵的,严格的入选标准和随访时间相对较短。EHR-driven基因研究可以分析大与健壮的临床数据和多样化的人群聚集在实际设置多年。研究人员可以快速和廉价地生成大型数据集的可能性直接指导临床医生的临床应用程序实时改善病人护理(25,26]。目前,电子医疗记录和基因组学(出现)网络正在“开发、传播和应用方法的研究,结合biorepositories基因发现和基因组医学电子医疗记录系统实现研究”(27]。
本文用Cornetet al。(3]表明,小说研究方法和资源可用于多环芳烃的病理生理学的进一步理解。带着新的、复杂的工具的未来多环芳烃诊断,治疗和预后取决于更精确的理解个人疾病表型直接预防策略,赋予个性治疗,改善预测。
脚注
利益冲突:E.M.贝克没有披露。
利益冲突:北达科他州哈顿没有披露。
利益冲突:J.J.瑞恩没有披露。
- 收到了2019年3月19日。
- 接受2019年3月20日。
- 版权©2019人队











{kind=link}
{kind=link}