





文摘
背景很少有研究调查和人工智能(AI)之间的合作潜力位肺脏诊断肺部疾病。我们提出,合作是胸腔和AI的解释(可辩解的AI(新品))优越的诊断解释肺功能测试(击球)比不支持治疗。
方法这项研究是在两个阶段进行的,一个monocentre研究(第一阶段)和多中心的干预研究每个阶段(阶段2)。利用两组不同的24击球的报道患者临床诊断金标准进行验证。每个击球解释没有(控制)和新品的建议(干预)。位肺脏组成的鉴别诊断提供诊断和优惠可选三个额外的诊断。主要终点相比精度控制和干预之间的优惠和额外的诊断。二次端点的诊断鉴别诊断,诊断信心和两分的协议。我们也分析了新品如何影响位肺脏的决定。
结果在阶段1 (n = 16位肺脏),意味着优惠和鉴别诊断准确性显著增加了10.4%和9.4%,分别控制和干预之间(p < 0.001)。改进有所降低,但高度显著(p < 0.0001)第二阶段(分别为5.4%和8.7%;n = 62位肺脏)。在这两个阶段,鉴别诊断中诊断的数量没有减少,但诊断信心和两分协议在干预显著增加。位肺脏更新他们的决策和新品的反馈和持续改进他们的基线性能如果AI提供正确的预测。
结论合作是胸腔和新品比个人更好地解读击球位肺脏独自阅读没有新品的支持或新品。
文摘
这项研究表明位肺脏时提高各自的诊断肺功能测试的解释基于ai的计算机支持的协议与自动的解释。这样的团队合作在未来可能变成司空见惯的事。https://bit.ly/3ZKK4Eu
介绍
当正确地解释,肺功能测试(击球)是一个有用的工具来解决呼吸道疾病的鉴别诊断1]。然而,击球的解释需要的专业知识结合的理解正常的价值观,肺功能模式(阻塞性、限制性、混合和正常)和煤层瓦斯的曲线在患者的病史,临床表现和其他诊断评估的结果2,3]。尽管存在各种算法来帮助解释击球(4,5),它已被证明,无论是位肺脏还是美国胸科学会(ATS) /欧洲呼吸学会(人)guideline-derived算法充分准确正确的阅读(188bet官网地址6,7]。
有人可能认为,人工智能(AI)可能有助于自动化驱动的过程的复杂推理解释击球。事实上,当所有的击球指数综合起来,呼吸系统疾病的基于数据的人工智能方法捕捉微妙的特点并不总是确定的临床医生,导致一个强大的算法鉴别诊断(8]。在过去,这种AI-driven算法已被证明单独执行,如果不是比位肺脏和可能有助于支持位肺脏解释肺功能(6]。然而,大多数临床研究报告通常AI优于临床医生的诊断性能上的比较(9,10],让位给一种非理性的声称,临床医生很快就会被AI-equipped设备所取代。与狭隘的人工智能的基于任务的范围不同,临床医生进行大量的职责涉及诊断、治疗和管理病人,同时也把移情医疗(一个至关重要的元素11]。虽然临床医生是不可替代的,还有一个巨大的潜力AI和临床医生共同努力改善常规临床结果(11]。目前,没有数据存在于AI和治疗之间的协作的好处在解释击球。此外,人工智能算法往往被视为黑盒,即。他们不能提供解释输出(12]。理解预测背后的基本原理是获得信任的关键,特别是临床医生计划行动基于算法的输出。另一方面,它也表明,解释可能有助于减轻自动化偏见和其他错误源于过度依赖人工智能系统(13]。今天,存在一些方法,使我们能够产生解释,呈现AI更加透明,因此更容易解读。这种人工智能的新范式叫做可辩解的AI(新品)14]。
在这项研究中,我们提出的帮助下胸腔的新品的建议将高级口译击球单独治疗工作。我们的主要目标是比较治疗之间的优惠和鉴别诊断准确性的观点(控制)和辅助治疗的观点与建议提供的机器学习模型(干预)6]。我们也比较干预是否比AI的独立的诊断性能。此外,我们研究如何援助后位肺脏更新他们的诊断选择新品。
方法
研究设计
在这项研究中重复措施设计,要求四位肺脏解释24匿名击球报告包括预处理和/或post-bronchodilator肺量测定法,肺容积,气道阻力和扩散能力(访问z得分和数据彩色编码显示偏离正常)。有限的临床信息(吸烟史和症状)也提供。每个击球报告被解读为在两个步骤:1)提供他们的反应控制步骤中位肺脏读完击球的报告,然后2)位肺脏的干预介入提供了他们的反应相同的报告建议的新品。因此,每个治疗48解释执行在一个运动。
我们在两个阶段进行研究。第一阶段(P1)是一个monocentric研究16邀请25位肺脏的鲁汶大学医院(比利时鲁汶)完成了研究。在第二阶段(P2), 62年88位肺脏邀请来自欧洲机构完成了研究(补充表S1)。P2被启动后,我们观察到主要终端P1得到满足。24集击球报告两个阶段之间的完全不同。
我们使用了大猩猩实验构建器在线平台进行研究[15]。参与者可以完成自己的节奏学习,没有时间限制。他们开始显示他们的知情同意,多年的临床经验(< 5或≥5年),与基于AI的任何经验的临床决策支持系统(Yes / No)和他们的热情在人工智能应用程序一般5分李克特量表上(辅料S2)。
之后,参与者被引导完成教程在线平台,熟悉新品的建议(辅料S3)。主要任务期间,位肺脏提供了鉴别诊断包括强制优先诊断和三个额外的诊断排名按优先顺序排列。诊断选择:1)健康或正常,2)哮喘(包括阻塞性或non-obstructive), 3)慢性阻塞性肺病(包括肺气肿和慢性支气管炎),4)间质性肺病(ILD)(包括特发性肺纤维化和对于肺纤维化),5)神经肌肉疾病(NMD)(包括隔膜瘫痪),6)其他阻塞性疾病(OBD)(包括囊性纤维化、支气管扩张和毛细支气管炎),7)胸畸形(TD)(包括胸膜疾病和肺切除术)和8)肺血管疾病(PVD)(包括肺动脉高压、血管炎和慢性血栓栓塞肺动脉高压)。
位肺脏也提供了一个总体诊断信心的5分李克特量表上(1 =至少信心,5 =最高的信心)。此外,他们指出他们的协议5分李克特量表与新品的建议(1 =非常不同意,2 =不同意,3 =中立,4 =同意,5 =非常同意)的干预阶段。辅料S3显示了一个示例的控制和干预阶段一个特定击球报告。
的道德委员会批准了P1 (S60243),而一个独立的伦理委员会批准了国际多中心P2阶段(S65162)。
击球的情况下
2017年11月至2018年8月在鲁汶大学医院,1003名受试者完成肺功能测试执行。击球时都是由呼吸道与标准化的设备执行运营商(Masterlab;Jaeger、维尔茨堡、德国),根据ATS /人标准(16]。全球肺功能行动方程被用来计算参考价值肺活量的用力呼气量在1 s (FEV1)、用力肺活量(FVC)和FEV1/ FVC [17),而1993年的欧洲共同体对钢铁和煤炭标准被用于扩散能力,肺容积和气道阻力测量(18]。一个临床医生分配一个八疾病的初步诊断在每个类别在794例指电子健康记录的临床历史,症状,击球和额外的测试报告。COPD患病率较高(23%),ILD(25%)、哮喘(9%)和正常(30%)主题特征样本。所有受试者白种人年龄超过18年。从这一组,我们入围92年主题,通过随机选择15个学科从每个最普遍的群体(慢性阻塞性肺病、哮喘、ILD和正常肺功能)和八个科目每个最普遍的疾病(NMD, TD PVD和OBD)。两位肺脏共同裁决的金标准诊断在这些情况下使用所有可用的临床资料包括击球。如果有分歧或怀疑诊断一个案例被选中最后一组24击球与金标准诊断病例,分别为P1和P2。在每一组中,我们随机从最普遍的疾病包括四个主题,两个科目最普遍的疾病。然后我们稍微夸大了AI错误地预测样本情况下的学习临床医生将如何应对不正确的AI的建议。位肺脏后额外的审查,在每组3例,正确预测的人工智能是故意被AI的情况没有正确地预测裁决金标准诊断。 Thus in both sets, the preferential diagnostic accuracy of the AI was set at 62.5% (15 out of 24 cases), which was lower than its reported validation accuracy of 74% [6]。
可辩解的人工智能
我们使用我们之前报道的机器学习模型,预测八呼吸系统疾病(慢性阻塞性肺病、哮喘、ILD、健康、NMD, TD, PVD和OBD) (6]。其优先诊断的准确性(计算概率最高的疾病)在inter-validation报道在74%,而相似的精度(76 - 82%)在测试过程中也观察到外部军团(6]。在这项研究中我们还报道解释AI的第二诊断建议其概率> 15%时,除了解释艾未未的优惠诊断。呈现可辩解的人工智能模型,我们使用一个博弈论的概念叫做夏普利值(sv)估计的证据不同击球指数对艾未未的诊断建议(19]。积极的SV解释作为证据支持模型的预测,而counter-evidence - SV。SV的大小表示强度的贡献。对于每个诊断建议,我们包括五大击球的SV情节指数大小降序排列的证据。我们也正常化sv他们除以级最高。我们展示的一个例子在击球的新品的建议图1。
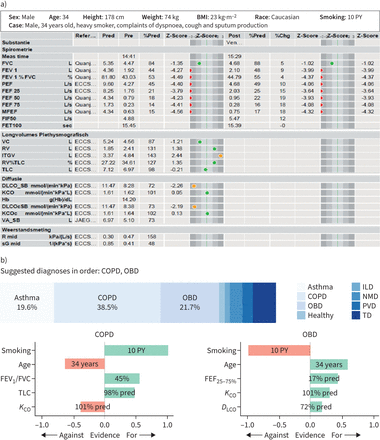
)一个示例肺功能测试(击球)报告(见[16- - - - - -18])和b)可辩解的人工智能(新品)的诊断建议夏普利值(SV)的证据。金标准诊断COPD是基于肺气肿在计算机断层扫描和被动吸烟暴露在儿童时期(正常的α1抗胰蛋白酶水平)。在这种情况下,新品让两个诊断建议(慢性阻塞性肺病和其他阻塞性疾病(OBD))从第二种疾病的概率(OBD) > 15%。此外,我们将展示一种正常化SV情节做出贡献的五大击球指数对慢性阻塞性肺病和OBD的预测,分别。积极的SV(绿色)是支持证据,而counter-evidence - SV(红色)。体重指数:身体质量指数;PY:久;ILD:间质性肺病;NMD:神经肌肉疾病;周围性血管疾病:肺血管疾病;道明:胸畸形; FEV1:在1 s用力呼气量;FVC:用力肺活量;K有限公司:肺的转移系数一氧化碳;FEF25 - 75%:用力呼气流量的25 - 75% FVC;DLCO:肺的一氧化碳扩散能力。
研究终端
我们的主要终点是比较位肺脏的优惠和鉴别诊断精度控制和干预之间的设置。平均优惠计算精度的情况下,一位肺脏的优惠诊断匹配的黄金标准,平均在整个队列。意味着微分计算准确性的次数一个位肺脏的鉴别诊断(包括优惠+附加诊断)诊断金标准,平均在整个队列。作为二级终端,我们探索了许多额外的诊断,临床医生的诊断信心总体诊断性能以及他们两分的协议优惠诊断。我们还分析了位肺脏如何更新他们的诊断决策之间的控制和干预,并进一步研究了如果位肺脏跟随的新品不正确的建议,指出自动化的偏见。
样本大小的计算
11位肺脏的最小样本量估计,使用双面配对t检验与假设之间的优惠和鉴别诊断的准确度控制和干预的意思是3例24例(12.5%),3例的标准差,0.05和0.8的力量的重要意义。的前提假设是,干预设置将显示平均提高至少10%的优惠和鉴别诊断准确性6]。
统计分析
我们评估量化端点使用配对t检验。Inter-observer协议优惠诊断选择是评估使用“κ弗莱斯。连续变量与同质假定为正态分布方差和Shapiro-Wilk正常的测试被用来测试的假设。我们执行的所有分析R统计软件(www.r-project.org)使用0.05的显著性水平。
结果
参与者人口
P1和P2看到16和62位肺脏的参与,分别为(补充表S4)。超过四分之三的参与者在两个阶段至少有5年的临床经验。超过一半的P1参与者与基于ai决策支持系统的经验,但这一比例在P2(11%)要低得多。意味着基线5分李克特量表对AI的热情在高两组(分别为3.56和3.92),表明整体偏向接受艾未未的决定。
击球时样本特征和基线的新品的性能
击球时样本特征类似于P1和P2 (n = 24) (表1)。样品包括四组的高患病率(慢性阻塞性肺病、哮喘、ILD和正常肺功能)和两种疾病的低发病率(NMD, TD PVD和OBD)。
艾未未的优惠将与金标准诊断15的24例(62.5%)在P1和P2样本,而其鉴别诊断(包括优惠+第二诊断诊断建议)金本位P1 22(91.7%)的情况下,21例(87.5%)的P2。人工智能的故障诊断性能在不同疾病组补充表S5。
主要终端
在P1,新品的使用意味着优惠和鉴别诊断精度提高了10.4%和9.4%,分别为(p < 0.001),这有点高于P2(分别为5.4%和8.7%;p < 0.0001)。因此,主要终端得到满足的意思是诊断精度控制(胸腔)和干预之间的显著增加(治疗+新品)(表2和图2)。然而,进步是小于预期从样本容量的估计(12.5%)。
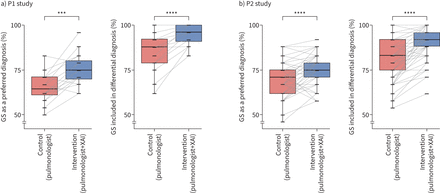
百分比变化之间的优惠和鉴别诊断性能控制(个人位肺脏)和干预(位肺脏和可辩解的人工智能(新品)))的第一阶段(P1)研究与16位肺脏和b)第二阶段(P2)研究62位肺脏。框表示中位数和四分位范围。* * *:p < 0.001;* * * *:p < 0.0001。g:黄金标准。
当我们比较了诊断性能的新品和干预之间设置(治疗+新品)作为一种探索性分析,我们也观察到平均提高13% (p < 0.0001)和3.1% (p = 0.01)的优惠和鉴别诊断准确性P1 (n = 16),这是类似于P2 (n = 62)平均提高12.25%和2.9%,分别。因此,我们注意到的帮助下位肺脏的新品的建议不仅提高他们的个人表现,但他们也显著优于艾未未的预测性能在P1和P2 (补充图S6)。
二次端点
我们在研究中包括的二级终端(表3)。在两个研究中,意味着李克特量表诊断信心显著增加(p < 0.01),而微分诊断选择控制和干预之间保持不变。弗莱斯的κ量化inter-clinician协议优惠诊断也增加了。位肺脏显示适度高水平的协议的建议新品。
Demographics-based性能
在P2 (n = 62),我们进一步分析的诊断性能增强的设置(治疗+新品)通过分层的经验。我们没有观察到显著差异在参与者之间介入诊断精度< 5年(n = 12)和≥5年(n = 50)的经验。同样,没有观察到显著差异当受试者分层基线的热情人工智能应用程序(补充表S7)。
改变反应
在这两个阶段,位肺脏的诊断反应改变之间的控制和干预几乎一半的24例(表4)。诊断信心在基线显著降低的情况下响应变化而保持不变情况下,响应。每当反应改变,我们观察到一个明显改善(p < 0.001)在鉴别诊断精度:55%改变病例的P1,鉴别诊断中包含78%的黄金标准控制臂与干预后的95%;在48%的改变情况下在P2,鉴别诊断包括73%的控制臂的黄金标准与干预后的91%。改变反应总是包含至少一个诊断建议新品。
自动化的偏见
我们研究如果位肺脏的性能减少之间的控制和干预当AI提出一个正确的或错误的优先诊断(分别为9例P1和P2) (补充表S8)。时发现优惠诊断准确性显著但略有减少的情况下诊断错误的新品,我们观察到大量增加新品时准确诊断是正确的。我们也观察到,位肺脏放置一个显著提高(p < 0.001)水平的协议与新品的建议的情况下正确的优惠与不正确的预测而不是优惠的预测,表明自动化偏见的风险很小。
讨论
在本研究进行的两个独立的阶段,我们观察到位肺脏当新品的协助下显著提高个人优惠和鉴别诊断准确性在解释击球。二级终端中,我们注意到诊断信心显著增加,但没有减少数量的鉴别诊断的选择。我们的研究结果支持假设是胸腔的新品的帮助下提高击球的解释呼吸道疾病的鉴别诊断与个人相比位肺脏没有支持。有趣的是,我们还观察到,位肺脏当新品的协助下显著优于新品本身在优惠和鉴别诊断的准确性。
大多数临床研究涉及人工智能一直强调的诊断优势AI使用一对一的比较(10),而很少有研究协作方法的好处。事实上,我们事后详细比较显示AI之间没有明确的诊断准确性的差异和个体位肺脏P1和P2。这通常是意料之中的事,因为不像大多数的研究,比较人工智能与非专家稀释人类平均性能,我们的参与者呼吸医学专家。很可能使用的新品将更加有益时所使用的医疗从业者缺乏经验的口译击球。虽然这不是我们的研究的目的,使用新品可以扩大到这些人群如果证明是有利的。其次,低于预期的改进也可以解释为包括我们故意击球的情况AI犯了错误学习的效果在临床医生的决策错误的预测。随机选择情况下基于实际患病率在现实的话就会看到更高的人工智能推高准确性和胸腔的表现以较大的优势。
合作方式的优越性与几种临床决策支持系统(cds)已报告提高从业者的性能在过去(20.]。我们的研究采用重复测量设计而不是安慰剂对照试验,不仅由于有限的可用性的参与者。我们还想创建一个设置的胸腔到达的诊断检查和更新,如果需要,基于一个自动化协议。虽然可能有一个元素通过重复测量设计的学习效果,我们的研究结果表明,新品的建议影响改变位肺脏在几乎一半的情况下的反应。当反应改变,位肺脏更有可能提高他们的基线性能。改变反应的分析显示更新后的诊断总是包含至少一个诊断建议新品。
我们的研究还允许一个初步调查自动化偏见,一个已知的错误,出现由于临床医生过分依赖信用违约互换的输出,即使它是不正确的13]。目前的结果显示,位肺脏优惠诊断性能略有下降当AI做出正确的预测,但是大大增加当一个正确的诊断建议。此外,协议的新品的建议是显著提高(p < 0.0001)与正确的建议与AI做出正确的预测,表明有限自动化偏见的风险。研究人员建议的解释,因为我们提供的sv,允许临床医生开发内部图片系统如何运作。它有可能减少错误的信任和依赖信用违约掉期(13,21]。尽管如此,没有解释的对照研究,必须进行最终建立自动化解释偏差的影响。
当前的研究符合小说ATS /人标准肺功能解释说明击球是呼吸系统的检测和量化干扰(22]。基于特定的模式,临床医生将使用击球的诊断检查中走向优惠诊断和鉴别诊断的减少列表。作为人工智能和新品算法提供诊断疾病的概率估计集群,但没有最后的疾病诊断,他们完全支持临床诊断过程。我们的研究的主要限制是我们定义的诊断优势作为一个积极的结果可能被视为缩小范围。在现实生活中,通过一个广泛的既往症的诊断检查,临床检查和呼出一氧化氮等多种测试分数和组胺的挑战,血液样本,甚至电脑断层扫描,没有可用位肺脏在当前的研究中。反之亦然,未来的人工智能模型也可能受益于多通道层的信息来改进他们的粒度和准确性。我们的研究也可以受益于一个更大的击球样本报告当前样本over-represents疾病像NMD, TD, OBD和周围性血管疾病。它扭曲了实际位肺脏疾病的患病率在临床实践中经常遇到。由于有限的样本容量和良好的个人临床医生的基线性能,引入人工智能的提高诊断准确性临床很小,可能不是很相关。种族多样性的缺乏也是一个主要的限制、阻碍当前外推的结果。在未来,使用随机临床试验设置前瞻性研究包括经验较少的实践者和使用击球更多元化的人口,与特定的端点等时间最终诊断,诊断或冗余测试,医疗系统的总成本,等。,需要建立真正的新品的有效性。
最后,我们的研究表明,位肺脏可以提高他们的个人诊断击球的解释与人工智能的帮助。AI和医生之间的这种团队合作在未来可能成为家常便饭,有可能推动医疗的提高尤其是在临床领域专业知识并不可用。
补充材料
可共享的PDF
脚注
利益冲突:n Das持有专利自动质量控制的肺量测定法。从基耶西大肠Derom报告咨询费用,葛兰素史克、阿斯利康和勃林格殷格翰的发言。g . Brusselle报告付款或讲座从阿斯利康谢礼,勃林格殷格翰的发言,基耶西,葛兰素史克公司,诺华和赛诺菲。f•布尔戈斯公司从医学图像诊断报告咨询费用。m . Contoli赠款费拉拉大学的报道,基耶西和葛兰素史克公司,咨询费用和阿斯利康的谢礼,勃林格殷格翰的发言,基耶西,葛兰素史克公司和诺华公司,以及从基耶西对参加会议的支持,阿斯利康、葛兰素史克和ALK-Abello。W.D-C。人是由一部分NIHR人工智能奖,和报告NIHR和英国肺脏基金会的资助,以及从Mundipharma谢礼,诺华,欧洲会议和DMC激励服务;和协会的名誉主席呼吸技术和生理(英国ARTP)。J.K.五胞胎报告从MRC赠款,HDR英国葛兰素史克、阿斯利康和基耶西,从Insmed和Evidera咨询费用。从基耶西大肠Vanderhelst报告赠款,咨询费用和从勃林格殷格翰集团谢礼,顶点和葛兰素史克。 M. Topalovic is part funded by a NIHR Artificial Intelligence Award, and is co-founder and shareholder of ArtiQ. W. Janssens reports grants from Chiesi and AstraZeneca, consultancy and lecture fees from AstraZeneca, Chiesi and GlaxoSmithKline, and he is co-founder and shareholder of ArtiQ. The remaining authors report no potential conflicts of interest.
支持声明:这项研究是由ArtiQ VLAIO科研资助和支持KU鲁汶(HB.2020.2406)。n . Das i Gyselinck和w·詹森是由佛兰德研究基金会(FWO Vlaanderen)。资金信息,本文已沉积的Crossref资助者注册表。
- 收到了2022年9月13日。
- 接受2023年3月9日。
- 版权©2023年作者。
这个版本分布在创作共用署名非商业性许可证的条款4.0。商业生殖权利和权限接触权限在}{ersnet.org







![a) A sample pulmonary function test (PFT) report (see [16–18] for details) and b) explainable artificial intelligence (XAI)'s diagnostic suggestions with Shapley value (SV) evidence. The gold standard diagnosis was COPD based on emphysema on computed tomography scan and passive smoke exposure during childhood (normal α1-antitrypsin levels). In this case, XAI makes two diagnostic suggestions (COPD and other obstructive disease (OBD)) since the probability of the second disease (OBD) is >15%. Additionally, we show a normalised SV plot of the top five PFT indices that contributed towards the prediction of COPD and OBD, respectively. A positive SV (in green) is supporting evidence, while a negative SV (in red) is counter-evidence. BMI: body mass index; PY: pack-years; ILD: interstitial lung disease; NMD: neuromuscular disease; PVD: pulmonary vascular disease; TD: thoracic deformity; FEV1: forced expiratory volume in 1 s; FVC: forced vital capacity; KCO: transfer coefficient of the lung for carbon monoxide; FEF25–75%: forced expiratory flow at 25–75% of FVC; DLCO: diffusing capacity of the lung for carbon monoxide.](http://www.qdcxjkg.com/content/erj/61/5/2201720/F1.large.jpg?width=800&height=600&carousel=1){kind=link}
{kind=link}
{kind=link}
{kind=link}