





文摘
炎症性肺部疾病是非常复杂的发病机理和炎症之间的关系,临床疾病和对治疗的反应。复杂的大规模基因表达分析方法量化(转录组)、蛋白质(蛋白质组学),脂质(lipidomics)和代谢物(代谢组学)在肺部,血液和尿液现在可用来识别定义疾病的生物标记物结合临床、生理和patho-biological异常。这些方法可以提高诊断的愿望是,即。定义病理表型,促进疾病的监测和治疗,同时,解决潜在的分子途径。生物标志物的研究既可以选择预定义的生物标志物(s)测量通过特定的方法或应用“公正”的方法包括检测平台中无差别的焦点。本文回顾了技术目前研究生物标记“组学领域内的肺部疾病。贡献个人的组学分析平台领域的呼吸道疾病是总结,提供背景的目标各自的能力有助于系统medicine-based肺部疾病的研究。
文摘
总结应用的omics-based分析平台在炎症性肺部疾病生物标志物的发现http://ow.ly/mjGGc
介绍
炎症性肺部疾病是非常复杂的发病机理和炎症之间的关系,临床疾病和对治疗的反应。尽管肺间质疾病长期以来被视为一系列的不同病理条件下具有不同的临床结果1),哮喘和慢性阻塞性肺疾病(COPD)最近才被认定为几位疾病实体组成的综合征2- - - - - -6]。复杂的、高通量、大规模分析方法量化基因表达,蛋白质和脂质以及其他代谢物在肺部,血液和尿液现在可用。这些方法提供可能识别定义气道阻塞性疾病的生物标记物的结合临床、生理和patho-biological异常。这些方法可以提高诊断的愿望是,即。定义疾病表型和促进疾病活动的监测和治疗。在研究方面,这些信息也将有助于解开复杂的分子途径基础疾病。
从广义上讲,生物标志物的研究既可以选择预定义的生物标志物(s)通过特定的方法或应用的“公正”的方法涉及使用不加选择的检测平台。本文综述当前可用的技术研究肺疾病的生物标志物在所谓的“组学领域,一个术语,最初是用于定义基因组的研究(基因)和基因表达的转录组细胞,组织,器官和生物和随后被采用的研究蛋白质(蛋白质组学),脂质(lipidomics)和代谢物(代谢组学)。最近,挥发性有机化合物的测定(挥发性有机化合物的仪器)呼出的气息凝结被称为“breathomics”。“组学词的使用反映了实验范式基于大规模数据集的获取从一个样本,目的是识别疾病的生物标记物和/或阐明小说功能或病理机制(图1)。“组学实验设计通常包括存活率存在组件广泛的包括数据集的获得提供洞察小说在疾病过程中,而不是集中在简化的“分子medicine-based”有针对性的方法。“组学方法是资源密集型的分析要求,需要使用复杂的统计和建模方法分析数据集组成的,成千上万的变量为了减少假阳性(错误)和假阴性(II型错误)。omics-based数据集的集合通常是系统生物学研究不可或缺的组成部分,寻求整合数据,从而理解关键波动homeodynamics实验系统的问题(即。疾病、表型、治疗干预)。不管选择什么技术,潜在发现生物标志物的诊断精度必须检查和验证根据国际建议基于STARD-guidelines [8,9]。
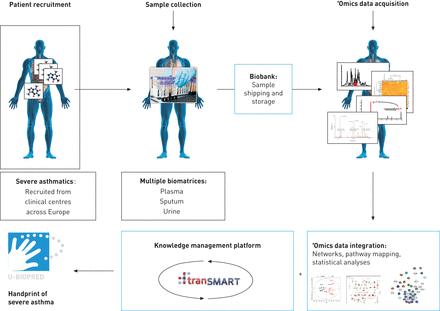
流程图的omics-based工作流无偏临床生物标志物发现受雇于雇用tranSMART U-BIOPRED项目作为其知识管理平台(7]。
主要生物矩阵可用于呼吸道疾病的生物标志物的发现:整个肺组织和肺实质细胞分离;支气管肺泡灌洗液(BALF);自发或诱导痰;呼出空气;呼出的气息凝结(EBC);血液(细胞,血清和血浆);和尿液。他们的应用程序的优缺点总结了各种“组学平台表1中提供的术语表表2。例如,肺组织包含组合转录组、蛋白质组和代谢组的多种细胞类型,复杂的分析和数据解释。相比之下,EBC可能蛋白质组的概要文件是太简单赋予有意义的生物标志物研究[10]。因此,重要的是,给定矩阵的潜在约束被认为在评估方法开发的任何讨论“组学方法综述。
“组学方法的一个重要的考虑因素是在生物样品中分析物的宽动态范围(12,13]。这可能导致更丰富的分析物的“挤出效应”更加丰富,因此要求方法丰富低丰度的组件,但在不利的价格对测定重现性的影响。这个范围内的浓度也会影响统计模型(如。使用单变量扩展与没有数据的扩展,这都使不同的假设关于数据的生物学意义)。分析是进一步复杂化一些分析物的物理化学多样性,如。蛋白质由于可变剪接,RNA编辑、亚基oligomerisation和转录后修饰(14]。脂质有广泛的多样性结构和物理特性,从中性分子,如甘油三酯和固醇,通过极地glycerophospholipids类花生酸等信号分子和其他oxylipins,包括众多的同分异构体。此外,开发方法很少考虑立体化学化合物的分析和识别,从而对观察到的生物参数产生深远的影响。这个结构和物理化学多样性,结合几个数量级的动态范围,导致大量的分析挑战与每一个不同的组学平台需要考虑方法开发matrix-specific基础上。此外,获得的各种数据结构提出了多个统计问题时集成来自不同的组学数据分析平台和生物矩阵(15,16]。
质谱分析概述
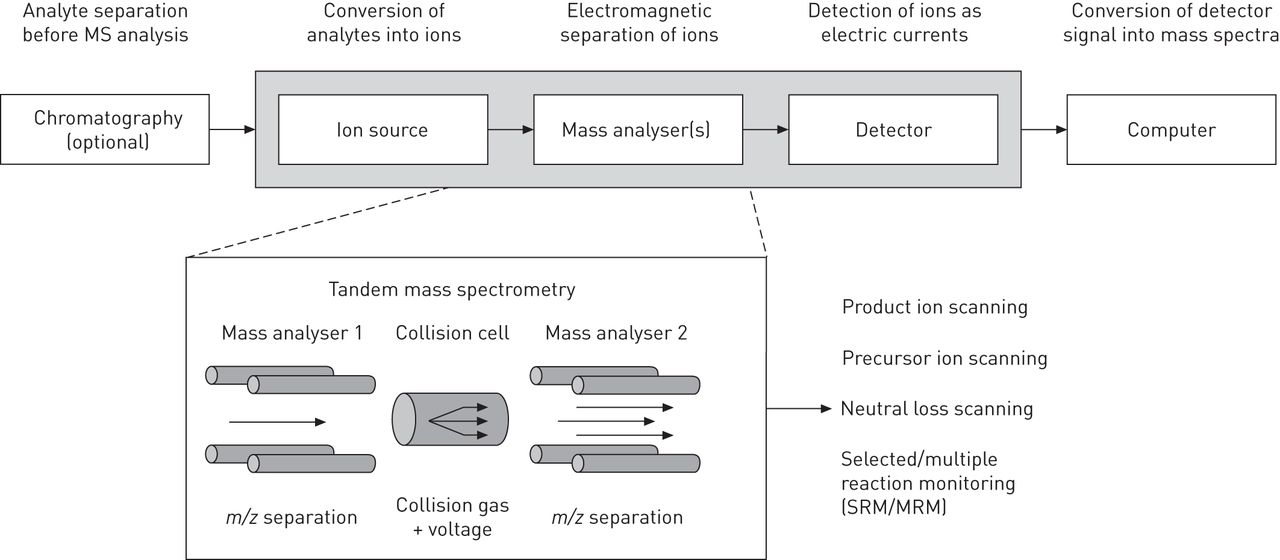
复杂性,因此权力,公正的生物标志物研究的快速增长是由于越来越组合可用的质谱分析方法。质谱仪使用质量分析器(确定分子的分子质量图2),它广泛存在于五个不同的格式增加质量分辨率和精度:四极,离子阱,飞行时间(ToF) Orbitrap和傅里叶变换离子回旋共振(FT-ICR)。使质谱的主要推进解决广泛的生物问题的发展电喷雾电离(ESI)作为电离的方法分析物;关键一步自质谱仪检测带电离子(17,18]。应急服务国际公司是一种软电离技术,费用分析物nebulising液体流从毛细管举行一个高潜力。离子产生的应急服务国际公司是稳定而不是其他软电离作用方法如matrix-assisted激光解吸电离(MALDI),产生的激发态离子迅速衰减。应急服务国际公司也导致更少的碎片,因此促进了分子离子的检测。这种进步使得检测的蛋白质,多肽,较为稳定脂质代谢产物相对简单,和应急服务国际公司目前最常用的技术分析物引入质谱仪。

质谱(MS)是一种分析技术,可用于确定质量,元素组成和化学结构的分子。在一个典型的配置目标分析物首先被转换成带电粒子(电离作用)在引入质谱仪。一旦进入,离子分离,根据他们的质量分析器m / z比使用电磁场在真空。分离离子然后记录探测器,探测器信号转换为质谱,可以存储和操纵电脑。质谱之前往往是某种形式的色谱法(气体、液体或薄层色谱法)分离之前感兴趣的分析物的分析。也是常见的质谱仪为目标有多个质量分析器操纵仪器内的离子。一种广泛使用的例子是三重四极质谱,第一个分析器是紧随其后的是一个碰撞细胞的碎片离子,和第二个分析器。该配置允许的扫描实验,可以用来阐明离子的结构,或增加仪器的灵敏度到一个特定的离子(s)(组)。
质谱方法不同的吞吐量(即。时间的分析),灵敏度和选择性,以及健壮性、易用性和成本。例如,表面增强激光解吸电离质谱(SELDI-MS)分离和捕获蛋白质子集表面基于特定的生物物理性质,如疏水性、净阴离子或阳离子电荷,之前由MALDI-ToF质谱分析。然而,缺乏分辨率和质量准确性阻碍明确识别的蛋白质峰(19,20.]。因此,识别候选生物标志物的肺病已经只有有限的成功21- - - - - -23]。大多数的组学的努力因此走向高分辨率的仪器,提供了更高的质量准确性促进物种的分子识别。例如,FT-ICR质谱仪目前提供质量最高的精度和分辨率,通常足够的计算基本公式,但它们相对的低吞吐量和昂贵的。Orbitrap技术为基础的系统界面的线性离子阱(LTQ Orbitrap)高质量精度和分辨能力,广泛用于omics-based应用程序(24- - - - - -27]。尽管他们或许会有质量分辨率低于FT-ICR系统(28],Orbitrap科技型仪器有更大的吞吐量,更健壮,更昂贵。重新崛起的离子迁移分离,分离带电分子根据他们的形状和构造,提供了一种正交分离的维度。最近,离子迁移分离结合quadrupole-ToF分析(29日),以及谱技术接口提高质谱分辨率成像(30.]。三重四极系统(MS / MS)使用多个/选择反应监测(MRM / SRM)是分析化学的重要组成,广泛用于量化蛋白质/多肽,脂质和代谢产物,部分原因是他们的鲁棒性和宽动态范围31日]。MRM提供最大的灵敏度分析物分离的高效液相色谱法(HPLC),尽管有限的光谱数据和质量分辨率的损失。质谱仪多才多艺,因此效用作为生物标志物的发现源自结合车辆质量分析器为混合分析平台,以达到广泛的特异性和敏感性。
方法直接注入高可溶性样品由ESI质谱仪增加再现性和极大地促进高通量分析,虽然牺牲简化复杂的混合物的分析物。直接注入已广泛用于猎枪lipidomics,雇佣了诊断前体和中性损失扫描特征的分子物种组成单独的类脂质(32]。因为所有的测量分析物在相同的电离作用条件下,他们很容易量化的使用适当的内部回收标准。应急服务国际公司的出现提供了一个简单的方法引入的洗出液液相色谱(LC)列直接进入质谱分析器,进而提供一个额外的分析维度,利用高效液相色谱柱技术的广泛分离分析物之前引入质谱仪。分离的色谱的选择使用数据生成的样本同样重要。临床生物标志物的发现,反相高效液相色谱相结合的应急服务国际公司是最常见的配置。最新进展包括转向高压感应系统,如超高效液相色谱(UPLC)和超高液相色谱法,提供了更高的分辨率、速度和灵敏度“omics-based方法。此外,新方法使用替代移动公司等阶段2目前已经开发出了(如。UltraPerformance收敛色谱法;通用产品2)。有多个静止阶段可用与质谱兼容,从疏水反向阶段(C18)列传统正常阶段亲水相互作用液相色谱(HILIC)和离子交换系统。毛细管电泳也被成功地耦合为“omics-based应用质谱(33]。此外,气体chromatography-based系统(GC)可以用于分离不稳定,热稳定的化合物的极性相对较低。这些系统已被证明有助于量化的许多小分子参与基本的新陈代谢,如。在breathomics方法(34,35]。
质/ MS分析的结合可以提供详细的成分和结构分析根据LC洗脱图,为增强灵敏度低丰度的组件。单和多维质/女士已经使用了所谓的“猎枪”蛋白质组学。一种方法,已成功应用于许多蛋白质组学实验室是多维蛋白质识别技术(MudPIT) [36]。虽然关注近年来一直专注于使用正交分离减少生物样品的复杂性,UPLC和nano-UPLC启用的高压功能的实现长列(即。50厘米)的高效分离生物样品(36和定量也被使用35]。最终选择分离技术和列取决于目标化合物的生物标志物的发现,因为目前没有方法是真正意义上的全球或综合能力获取一个完整的蛋白质组,lipidome或代谢物。
转录组
能够确定RNA转录的微分表达式(转录组)随着时间的推移和/或细胞和疾病之间改变了我们对细胞功能的理解(37]。旨在描述和量化RNA转录组分析物种如mrna,非编码RNA和小RNA,及其变化,以应对外部刺激或疾病。表达分析微阵列非常成功和广泛使用,例如,000年> 40引用目前在PubMed [38]。使用微阵列可以探测的表达的变化很多,但不是全部,转录基因在正常和摄动条件下。直接测序提供了潜在的检测记录及其变体,但依赖于一个不太成熟的技术。
改善微阵列分析和解释是由于世界各地许多团体共同努力,引入质量控制标准和指南完成微阵列工作流(39- - - - - -42]。这些进步花了10年时间建立微阵列,但应该更迅速地解决新兴技术(39,40]。RNA序列(RNA-seq)提供了几个优势微阵列和在不同物种生成的重要成果43- - - - - -45]。它完全被认为是公正的,因为它不依赖于一组预定义的探针阵列芯片选择,覆盖整个转录组,使小说的发现外显子,亚型,甚至先前未被发现的成绩单(45]。此外,RNA-seq方法背景噪音较低,动态范围大,高度准确、重现性好,生产数据与微阵列(45,46]。然而,使用的一些特定的协议可能引入偏差由于放大,碎片和结扎过程有一些序列偏好(37,40,47]。这两种方法的限制是使用RT-qPCR需要验证表达式的值。新兴技术,使用微型高通量RT-qPCR方法或多路直接可视化和计数的RNA分子已经被开发出来,但这些方法必须标准化跨平台和应用(37,40]。当前微阵列的优点包括其相对较低的运行成本与测序以及成熟的分析策略和实验设计来处理已知的固有偏见在微阵列数据38]。
转录组肺疾病中的应用正在改变我们的观点在慢性肺疾病的分子分类,以及开放的新途径使用疾病生物标志物发现组织或代理细胞和监测药物反应(48,49]。例如,微阵列的使用已确认的存在不同的子集轻/中度哮喘病人的基础上Th2细胞因子的表达,表明基因表达谱在气道上皮细胞可以预测药物反应(50]。患者人群表达高水平的Th2细胞因子,所谓Th2-high表型,表达不同的气道炎症的特点在一个连续的变量,与当地和系统性措施显著相关的过敏和嗜酸性粒细胞(51),反应,糖皮质激素比Th2-low表型(50),也与气道重塑的标志(50]。高periostin Th2-high表型水平也被证明能够区分严重哮喘患者应对anti-interleukin-13抗体疗法(52]。
微数组技术也被用来区分mRNA外周血CD4的表达谱+在频繁和罕见的喘息患儿t细胞由于病毒暴露53),来展示不同的microRNA在CD8概要文件+从严重和不重的哮喘患者t细胞分离54]。哮喘动物模型,结合过敏原的微阵列而且证明了深刻的影响和病毒对小鼠肺癌基因表达,从而强调toll样受体的关键作用,小说丝氨酸蛋白酶抑制剂以及招募炎症细胞的趋化因子和细胞因子的气道(55]。以类似方式,Tilleyet al。(56]分析了香烟烟雾对转录组的影响模式在小气道上皮细胞(56和肺泡巨噬细胞57),并演示了差异表达谱在一些“健康”吸烟者可能与COPD的发病机制(57,58]。氧化应激效应的关键作用在驾驶COPD气道上皮细胞也演示了使用基因微阵列(59]。
微阵列之间的直接比较和RNA-seq进行支气管上皮细胞不吸烟者和吸烟者肺癌有或没有。结果显示两种技术之间的显著相关性虽然RNA-seq发现吸烟和癌症相关的记录比微阵列(60]。同一研究小组能够展示一个转录组读数之间的相关性分析微阵列和蛋白质组学61年],它突出的存在改变了蛋白表达在缺乏微分转录。制药行业使用微阵列分析疾病和药物影响无数的细胞和组织使用标准程序,平台(如。Affymetrix微阵列)。数据库能够整合这些数据与病人临床资料,代表的主要因素在药物发现中使用微阵列(37,40]。然而,需要进一步的分析样本的相关性疾病的网站来验证检测差异(37,40]。
总结
当前先进的关于药物发现仍由微阵列由于表达分析:1)成熟可用的工具/平台;2)现有的数据可供比较的目的;和3)相对较低的成本。然而,正在进行的研究对标准化深度排序的方法和比较的结果排序和微阵列分析相同的样本会导致分析项目,使直接比较两种技术(38]。较低的检测基因表达对这两种方法仍将是一个问题,但也有一些应用程序,比如成绩单发现和同种型识别,RNA-seq是首选方法(38]。随着测序成本的降低和新一代测序平台的可用性的增加,一个开关的方法将在未来几年内逐步发生。然而,鉴于这两种方法之间的实质性的协议,不太可能产生的微阵列数据目前或在现有数据库将成为过时。相反,这些信息可能会补充和扩展深度和报道的序列数据,提供更深的洞察呼吸生理和疾病。此外,mrna的表达水平的面板将为疾病生物标志物(子)类型和新型药物的功效。
蛋白质组学
量化的蛋白质被大量研究的基础肺疾病,但直到最近,公正的蛋白质组学方法,结合质谱与凝胶-或non-gel-based蛋白质/肽的分离方法,已使用(62年,63年]。宽的蛋白质识别在很大程度上取决于应用的方法,因为每个检测蛋白质具有不同的选择性和灵敏度。一些方法主要是描述性的,而其他人更量化。例如,GeLC-MS / MS定性技术用于定义人类唾液的蛋白质组(64年),最近被应用于分析BALF中鼠标和non-primate哮喘模型,在疾病相关的特定的生物标志物对皮质类固醇治疗被确定(65年]。
任何蛋白质组学研究的一个主要目标是量化与疾病相关的潜在生物标志物。SELDI-ToF-MS已广泛应用于呼吸系统的一些研究。例如,血清淀粉样蛋白(SAA)被这种方法确定为慢性阻塞性肺病急性加重的小说血液生物标志物,这证实了ELISA (66年]。因为SAA水平与感染,感染或急性加重的研究表明一个角色而不仅仅是慢性阻塞性肺病。其他SELDI-MS BALF的分析已经确定CCSP10,中性粒细胞defensins 1和2,calgranulins 1和2 (S100A8和S100A9)是改变与慢性阻塞性肺病吸烟者相比,无症状吸烟者(67年]。然而,尽管改进技术和设备的相对购买力,SELDI-ToF-MS平台还没有提供足够的分辨率或再现性用于临床诊断。这主要是由于缺乏质量准确性和漂移数据收集期间,很难明确地识别蛋白质峰(19,20.]。
其他定量研究应用不同的蛋白质质谱分析前分离的方法。Nicholaset al。(68年)使用二维凝胶电泳分离蛋白质诱导痰液样本COPD患者和健康的吸烟者在MS / MS分析。他们确定了44个差异表达蛋白质点在慢性阻塞性肺病,其中两种是通过免疫印迹分析进一步验证和ELISA: lipocalin-1和载脂蛋白A1。有趣的是,大多数的差异表达蛋白质减少慢性阻塞性肺病和他们中的许多人可能与先天免疫相关功能。改进的微分形式的二维凝胶电泳的蛋白质标签与多个染料最近强调的效用二维凝胶技术寻找生物标志物的肺部疾病等具有挑战性的biofluids痰(69年]。K奥et al。(70年)最近utililised多路复用差异凝胶电泳确定一个以女性为主的subphenotype慢性阻塞性肺病。在这项研究中,一个子集肺泡巨噬细胞主要来自19个蛋白质的溶酶体活性和氧化磷酸化途径被发现提供分类的女性COPD患者78%的预测能力。二维凝胶方法的持久吸引力在于易于定量生物标记和识别,识别为代表的慢性阻塞性肺病的保利免疫球蛋白受体作为生物标志物。
虽然二维凝胶电泳提供优秀的分辨能力,这种方法有一些限制(71年),包括有限的能力来解决蛋白质与极端的分子量和等电点和精确调整个别蛋白质斑点的挑战不同的凝胶比较患者群体。因此,gel-free方法,比如稳定同位素标记的方法(iTRAQ,等压标签进行相对和绝对定量),曾,一个例子是识别生物标志物研究吸烟的人血浆样品中(72年]。在这里,作者通过损耗的增加蛋白质组覆盖14个最丰富的蛋白质,确定113年低丰度蛋白,其中16吸烟者和非吸烟者之间的差异表达。iTRAQ方法,再加上nano-LC-LTQ-Orbitrap,也被用于比较支气管活检样本的蛋白质组和哮喘健康者和糖皮质激素治疗反应的识别差异(73年]。大量蛋白质中发现尽管有限的材料进行分析,缺乏丰富的蛋白质的消耗。七个蛋白质差异表达相比在哮喘控制和七个被修改布地奈德治疗的反应。
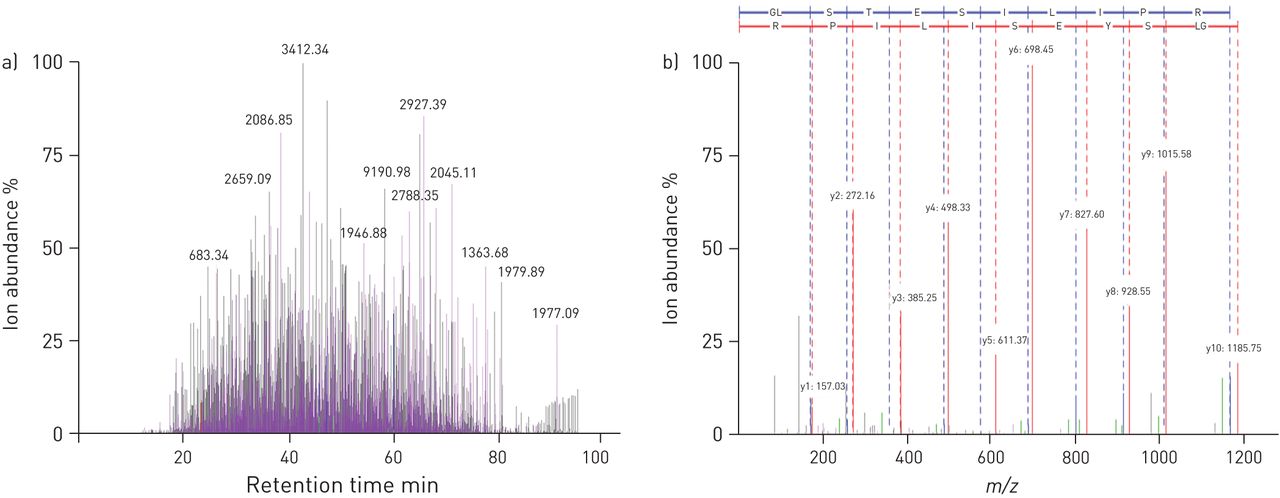
质谱分析仪器领域的进步(增加灵敏度,分辨率和质量准确性),LC分离和生物信息学已导致label-free方法成为蛋白质组学分析的方法选择(图3)。这是因为这种方法提供了一个快速、简单和低成本的测量的蛋白质表达水平在复杂的生物样品。Gharibet al。(75年)与定量label-free方法使用基于光谱计算分配17个差异表达蛋白质诱导痰。这个子集是丰富与过程相关的蛋白质在蛋白酶抑制活性,防御反应,免疫和炎症;该方法分类哮喘和对照组。进一步研究使用FT-ICR质谱识别的亚型SP-A BALF的囊性纤维化患者,慢性支气管炎,肺肺泡蛋白质沉积症观察定性差异SP-A亚型患者肺肺泡蛋白质沉积症相比其他疾病的检查(76年]。然而,现在接受的是,一个蛋白质复杂疾病的生物标志物不太可能足够的疾病分类和诊断,一个成功的策略将由开发小组的生物标记物(77年]。令人印象深刻的是,研究特发性肺炎综合征识别出一套81年的疾病有关的蛋白质生物标记使用label-free方法和能够分层患者细胞因子可能有的反应,中和治疗(78年]。
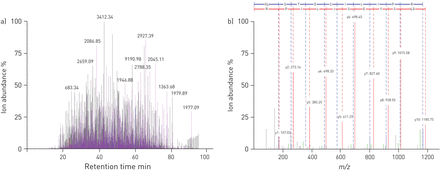
分析人类诱导痰液使用label-free方法分析,质E,年代ilvaet al。(74年]。获得LC-ion色谱的)肽以痰液和b)的MS / MS谱肽([M + H) 2+m / z从lipocalin-1 = 1185.68)确定。
总结
当前最先进的呼吸样本的蛋白质组学分析使用定量label-free质方法提供:1)改善(更快、更敏感)检测的蛋白质的生物样品类型;2)相对和绝对定量(ng·毫升−1);和3)与多路复用的方法,如iTRAQ提供独立的数据收集的样本,在理论上允许理论上无限数量的临床样本的比较。质谱分析仪器的技术进步和信息提供了一个令人兴奋的前景的未来在呼吸道疾病诊断和预后标志物的发现。这样的进步包括应用无偏data-independent质收购策略(74年),使信息从生物样品获得最大化获取准确的质荷(m / z)所有前体离子比率值及其对应的碎片离子在单个运行分析。这些几乎完全数据随后可以审问后分析,不仅对多肽和蛋白质,而且对其他目标分子如脂质和代谢产物,促进“一站式”多维生物标志物的发现。然而,尽管最近的质谱分析仪器的进步,分析目前的速度限制,是一个关键的挑战未来的临床蛋白质组学。前端的小型化的进步通过nanospray微流体分离(79年)可能提供一个解决方案来解决这一挑战,提供进一步的敏感性和样品处理量增加,一个重要的先决条件的出现个性化蛋白质生物标志物的发现。
Lipidomics
脂质构成∼90%的肺表面活性剂,这是至关重要的维持小气道和肺泡效力,他们扮演了一个重要的角色在肺部疾病。讨论在肺脂质可分为1)丰富的结构或分子脂质(如。磷脂)和2)low-abundance信号脂质(如。类花生酸)。脂质可能有一个主要角色,改变脂质成分,生物合成或下游代谢影响直接在恶化和疾病严重程度。另外,脂质成分可以改变疾病过程的结果,从而提供生物标志物来分层状态,监测药物的效果,或者预测恶化的可能性。此外,脂质代谢的生物学重要性产品由细胞形成膜相关花生四烯酸在大量研究已经证明(80年),虽然结构类似的化合物的生物作用尚不清楚。
磷脂酰胆碱
的glycerophospholipid磷脂酰胆碱(PC)的主要脂质类肺表面活性剂,降低总脂质含量的一半。这在痰液表面活性脂质减少,但不是BALF [81年的哮喘病人,这表明成分改变BALF PC血浆渗透相关的航空公司而不是改变表面活性剂的新陈代谢在肺泡82年]。因此,治疗哮喘患者与外源性表面活性剂有“正常”电脑的内容可能会是有益的(83年,84年]。Lysophosphatidylcholine (LPC),由中国人民解放军2活动的电脑,会导致肺部疾病的发病机制,包括急性呼吸窘迫综合征(85年]。抗原的挑战在哮喘动物模型的浓度增加肺泡II型特异性解放军2同种型,减少表面活性剂磷脂,治疗特定的解放军2抑制剂显示疗效[86年]。有趣的是,蛋白质表面活性剂抑制这个II型特异性解放军2酶。
Phosphatidylglycerol
Phosphatidylglycerol微量组分的典型的哺乳动物细胞膜,但它是第二个最丰富的表面活性剂磷脂,它促进了电脑的吸附空气:液体界面。分泌解放军2优先结合和酸性水解磷脂phosphatidylglycerol,当地在哮喘过敏原的挑战对象导致减少大量phosphatidylglycerol和PC phosphatidylglycerol比增加,表面张力差的相关功能(87年]。额外的角色phosphatidylglycerol绑定toll样受体4提出了virally-induced哮喘急性加重;治疗支气管上皮细胞与phosphatidylglycerol减少炎症反应呼吸道合胞病毒(RSV)和肺安装phosphatidylglycerol小鼠显著降低他们对RSV感染的易感性88年]。最近,减少phosphatidylglycerol在呼出粒子被描述为哮喘受试者相比,控制志愿者(89年]。
Sphingosine-1-phosphate lysophosphatidic酸
Sphingosine-1-phosphate (S1P),由鞘氨醇合成kinase-mediated磷酸化的鞘氨醇(90年),是在BALF的哮喘患者抗原升高的挑战[91年)和等效果,刺激气管平滑肌的收缩(92年]。蛋白质是监管机构的“Orm”家庭的鞘脂类合成93年ORMDL3内)和单核苷酸多态性位点与严重的儿童哮喘相关(94年),可能影响S1P的生产和哮喘的发展。Lysophosphatidic酸的作用(LPA)是由autotaxin LPC的和可以提高气管平滑肌收缩性(95年,96年]。BALF LPA水平已被证明增加敏感哮喘小鼠模型,观察一个直接联系LPA2受体的表达与肺部炎症(97年]。
二十烷类
类花生酸组成一大群生物活性的信号分子产生的酶和auto-oxidative过程从花生四烯酸和其他膜结合多元不饱和脂肪酸。oxylipin一词被引入作为一个包含标签由脂肪酸形成的含氧化合物的反应(s)包括至少一个一步单链不饱和脂肪或是dioxygenase-catalysed氧化。因此,这个术语包括知名二十烷类花生四烯酸的合成,以及相关化合物氧化形成的多不饱和脂肪酸的长和短链的长度。有成千上万的潜在的类似物不同脂肪酸的合成前体(如。DHA和EPA),其中大部分还在待定生物角色。信用证的使用较低的粒子大小和MRM质谱最近成为可能量化数以百计的这些分子同时[98年,99年),提供洞察他们的角色在呼吸道疾病80年]。分析类花生酸的一个特定的优点是测量表明尿代谢物的通常是一个敏感的监测肺生物合成方法。特别是泌尿类二十烷酸资料可以反映哮喘发作或诱导的支气管收缩,例如,过敏原的挑战。这是可能的,因为休息二十烷类及其下游代谢物水平非常低,而有大量增加在其诱导后释放到循环新创生物合成,综述了Kupczyket al。(One hundred.]。
前列腺素氧化后产生的花生四烯酸环氧酶(COX-1或COX - 2)和具体的前列腺素合成酶分为五个主要考克斯产品:铂族元素2,PGD2,PGF2α,PGI2与凝血恶烷2(酸2)。可以说研究前列腺素是铂族元素2著名,但在肺部病理复杂,作用101年]。铂族元素2有支气管扩张剂的影响,抑制反应的过敏原和其他引起的支气管收缩,肥大细胞可能通过抗炎效应(102年]。相比之下,PGD2,连同其早期出现代谢物9α,11β-pgf2受试者中,使支气管哮喘(103年- - - - - -105年]。9α,11日β-metabolite和tetranor-metabolites可以测量血液和尿液,并作为内生PGD指数2,由肥大细胞生物合成。在哮喘患者,尿浓度9α,11β-pgf2增加对过敏原反应和其他气道阻塞的触发因素。哮喘病患者有较高的尿PGD tetranor代谢产物的水平2比non-asthmatic对照组,而铂族元素的含量2具有可比性(106年]。氨甲环酸2是一个强有力的支气管收缩的,被认为是哮喘治疗的目标。产品11-dehydro-TXB形成的酶的水平2然而,更可靠的指标内源性酸吗2生物合成,11-dehydro-TXB2增加在过敏性哮喘患者的尿液allergen-induced支气管狭窄(107年,108年]。
白细胞三烯(LT)是由5-lipoxygenase (5-LOX)催化转换LTA花生四烯酸4(109年),随后要么LTB转换4通过英国网球协会4水解酶或半胱氨酰白三烯等(CysLTs)通过LTC4合酶。类似的路径存在通过15-lipoxygenase活动,导致合成lipoxins eoxins以及相关hydroxyeicosatetraenoic酸(het)。CysLTs是强大的人类气管和血管平滑肌收缩受体激动剂(110年- - - - - -112年]。LTE4在很大程度上是没有额外的新陈代谢,增加尿液中尿LTE吗4疾病严重程度的水平是用作生物标记(如。哮喘急性加重)[One hundred.]。有大量的证据表明,监测尿LTE4提供了有价值的信息机制的炎症在哮喘等呼吸道疾病80年]。Lipoxins (LX)是短暂的二十烷类,可以支持的分辨率炎症(113年]。研究测量lipoxins建议LXA的保护作用4和15-epi-LXA4在哮喘114年,115年]。het一羟基的脂肪酸,主要是生产通过液态氧代谢(5-LOX和12/15-LOX在人类116年),虽然他们也可以生成non-enzymatically。脂质中介15-HETE是主要的花生四烯酸代谢物在人类支气管(117年),几项研究表明,高15-HETE水平表明炎性反应在哮喘118年,119年]。生物合成的反应类似于CysLTs, 14日15-LTA4可以进一步转化为eoxins 14日15-LTC吗414 15-LTD414、15-LTE4(120年]。eoxins的生物学功能尚不清楚,但重要的例外4水平的患者BALF中观察到一系列的疾病,包括嗜酸性肺炎和哮喘(121年]。Eoxin水平升高EBC从相对健康的儿童哮喘,结果表明哮喘严重程度之间的关系和Eoxin水平(122年]。
Isoprostanes,来自花生四烯酸通过自动氧化,主要研究了氧化应激的标记在肺部疾病123年,124年]。尽管他们不是酶产品,他们具有不同的生物活性。肺动脉高压患者增加了isoprostane水平相对于健康对照组,和吸入的响应没有相关基础水平的这些化合物(125年]。在氧化肺部疾病的标志,8-iso-PGF2α是一个很好的候选人研究氧化应激的影响,因为它显示了强大的平滑肌收缩性质在体外通过FP的激活受体(126年]。事实上,高尿8-iso-PGF水平2α已经记录在外在过敏性肺泡炎患者(127年,128年]。
总结
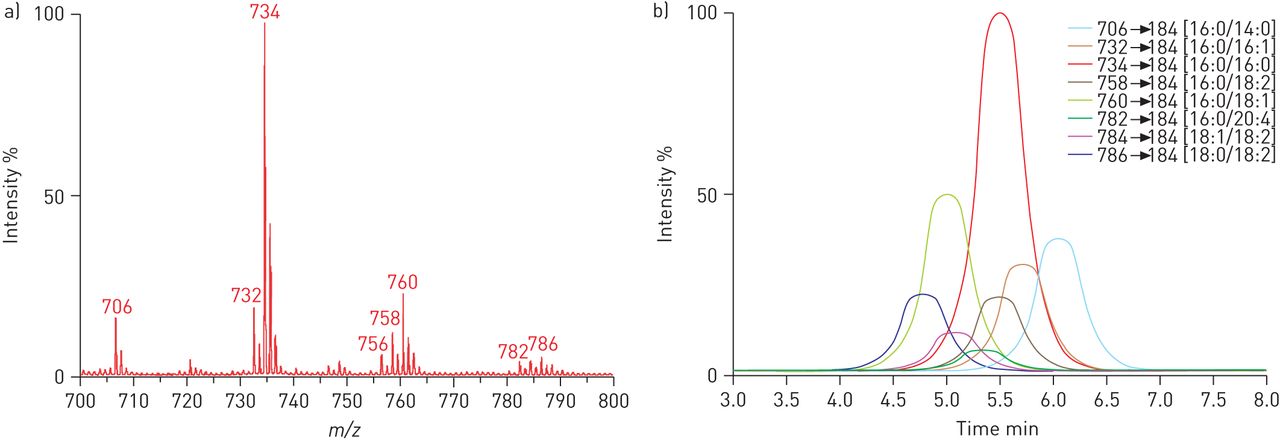
脂质在呼吸道疾病的相关性良好,并且有充足的理由加入系统的基于努力识别生物标志物,探索疾病的机制。当前最先进的lipidomics涉及的组合快速扫描串联MS / MS和高分辨率质谱仪(如。Orbitrap科技型系统)来识别个人脂质物种(图4)。这些平台提供多种优势,包括:1)提高精度;2)进行结构确认实验的灵活性;和3)格式为相对高通量分析。最新进展包括lipid-based信息学的发展资源,如脂质地图Lipidomics网关和特定lipid-based软件(如。LipidView、SimLipid LipidXplorer)旨在帮助识别多种脂质物种在一个单一的分析,和确定的位置的半个分子脂质分子中不饱和键脂肪酸(129年]。当前质方法的限制是无法进行精确的量化由于缺乏真正的分析标准,而且经常与物种的大量收购co-elute lipidomics分析方法。结合数据库的缺乏或光谱库化合物鉴定,这使得常规lipidomics挑战性。能够识别和量化个人脂质物种仍然是大多数lipidomics研究的主要障碍;然而,预计未来技术进步将大大增加我们的能力量化此类复杂lipidomics概要文件。
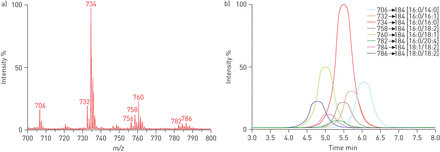
)直接输注全扫描和b)多反应监测(MRM)质谱人类支气管肺泡灌洗脂质提取。直接注入的例子,介绍了样本直接进入质谱仪未经分离和一个完整的质谱的离子(全扫描)没有碎片了。这是一个快速的方法筛选样本的脂质成分,但不产生任何分子质量以外的结构信息,并可能缺乏敏感性检测分析物发生在低丰度的样本。MRM例子的分析物立即由液相色谱分析之前,提高灵敏度。此外,质量分析器都设置为只检测一个特定的质量;第一个分析器选择性措施前体离子,然后在碰撞中支离破碎细胞,第二个分析器选择性的措施之一,其碎片(离子)的产品。这允许非常特殊和敏感的筛查的目标分析物,使用已知的过渡是一个分子的分裂模式特征,尽管忽略其余的成本组成的样本。
代谢组学
代谢组学的定义是“整个代谢物的分析在一个给定的一组生理、环境和/或临床条件”(130年]。代谢物变化的确切的定义,但一般被认为是“定量补充所有低分子量的分子在特定生理或发展型国家”(如。代谢物的代谢过程、细胞、组织、器官或生物)131年]。呼吸系统疾病的应用代谢组学的研究正处于起步阶段,落后于其他疾病(如。癌症和心血管疾病)。它提供的能力1)特定的呼吸系统疾病和sub-phenotypes分类(如。温和的与严重哮喘)和2)确定一个“量化疾病表型”(即。具体配置文件/代谢物浓度的诊断或预后疾病)[132年]。很多最初的呼吸代谢组学研究领域进行了核磁共振(NMR)谱由于其易于应用和非破坏性自然,但也越来越多地使用质谱,因为改进的敏感性和特异性。
最初的应用代谢组学方法在哮喘的研究中被证明是有前途的。NMR-based代谢组学研究发现70尿代谢物集体判别模型的稳定哮喘患者以及加剧哮喘患者的典范与稳定的哮喘患者,都有94%的准确度(133年]。鲁棒多变量模型(偏最小squares-discriminant分析)确定23代谢物改变,柠檬酸循环代谢产物明显增加的两种分类模型(琥珀酸、延胡索酸酯、草酰乙酸、2-oxoglutarate和cis-aconitate)。米attaruchiet al。(134年)成功地分类范围的过敏性哮喘状态使用多变量模型(潜在structures-discriminant分析正交投影)产生一道质分析的尿液。第一个模型区分哮喘患者和健康对照组有98%的准确度,第二个区分药用和non-medicated哮喘病患者的准确性达96%,第三个分离——和哮喘患者控制不好的准确性达100%。在哮喘集中调查显示减少排泄的尿刊和methyl-imidazoleacetic酸代谢物类似一个Ile-Pro片段。Carraroet al。(35]使用核磁共振的EBC分类哮喘的准确性达86%,这是一个轻微的改善基于呼出没有81%的准确率,在1 s (FEV用力呼气量1)。
核磁共振分析血清分化温和(全球倡议慢性阻塞性肺疾病(黄金)III)从严重的慢性阻塞性肺病(黄金IV)的准确性达82% [135年]。从健康对照组病人的歧视是由于减少水平的支链氨基酸(BCAA)缬氨酸和异亮氨酸,减肥的结果可能由于蛋白质水解恶病质患者因为BCAAs已被证明与身体质量指数(135年]。代谢物的质分析等离子体成功地分类气性COPD患者和non-emphysematous 64.3%使用层次聚类的准确性136年]。然而,多元建模(线性判别分析)的前七个生物标志物(其结构不确定)分类精度提高到96.5% (136年]。核磁共振分析EBC成功模仿稳定的囊性纤维化患者96%的准确性(91%的准确性和特异性96%)。第二个模型分化不稳定囊性纤维化的准确性达95%(86%的准确性和特异性94%)(137年]。
总结
高分辨率LC-MS-based平台目前代表代谢组学的前沿技术由于:1)能同时测量了大量的不相关的代谢物;2)能力分析代谢物与广泛的化学性质;和3)相对直接样品制备与其他代谢组学技术。代谢组学中最重要的进展之一是kit-based技术的发展如BIOCRATES[销售的138年]。这些技术非常简单,说明潜在的代谢组学分析成为一个常规组件的组学工具。然而,代谢组学方法有很多局限性;首先,当前没有平台可以测量样品中的所有在场的代谢物其次,缺乏数据注释工具,这意味着只有一小部分的信息在一个数据集可以适当解释。因此,最重要的发展领域需要开发工具或方法来处理这些限制。到目前为止,大多数的呼吸道疾病代谢组学研究主要集中在开发和验证的方法;然而,在未来的代谢组学将扮演重要的角色在识别疾病的生物标志物和阐明机制。模型的分类精度高产生的材料收集动物(如。尿液)表明,代谢组学可以在歧视中发挥核心作用的疾病和定量表现型。一个长期目标是能够确定预后和/或代谢产物与疾病的诊断模式。此外,单个代谢物的身份负责区分呼吸道疾病患者和健康对照组将提供有价值的信息对疾病的代谢机制。因此,预期的应用代谢组学方法(核磁共振和大规模spectrometry-based)将显著增加。
Breathomics
呼出空气中包含一个复杂的混合物的气相139年)和非易失性化合物来源于凝聚水汽和气溶胶粒子(所谓EBC) [140年]。呼出代谢物的起源不同,因为他们的结果从系统性和局部代谢,炎症和氧化活动。呼出空气分析的优点是它的本质。呼出空气中代谢组学方法目前被称为“breathomics”。检测单个分子化合物挥发性有机化合物的仪器的标准气(141年),但其他先进的分析设备,如质子转移反应质谱(ms)、离子迁移谱,和选择离子流管质谱(SIFT-MS),也可以使用。合并后的分子组成的气体混合物可以通过电子鼻评估(以挪士)142年,143年基于阵列的纳米传感器,不确定个人化学成分的相互作用模式。以挪士的输出是一个标志性的挥发性有机化合物的混合物,可以视为一个复杂的气体混合物的指纹(图5)。有几个原则支撑电子鼻传感器,包括导电聚合物、金属氧化物、金属氧化物场效应晶体管、表面或体积声波,光学传感器,比色传感器、离子迁移谱法、红外光谱法、gc - ms(金纳米粒子,142年,143年]。分析的电子鼻数据涉及到模式识别算法开发的复杂特征,呼出空气混合物(breathprints) [146年]。Breathprints可以通过训练有素的狗和歧视这一观点促进了嗅觉和信号通路的研究开发新的分析技术(147年]。EBC可以通过几乎任何分析(生物)试验的限制检测代表最常见的问题。代谢组学的EBC通过核磁共振光谱学是目前最有前途的方法(见下文)35,137年,148年]。
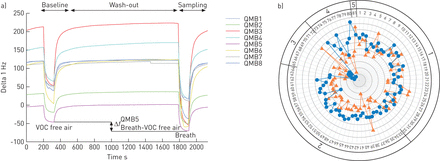
Breathprints以挪士。)典型breathprint从哮喘患者获得非商业电子鼻组成的八石英微量天平(QMB)气体传感器覆盖金属的分子的电影。变位代表响应(传感器频率变化)挥发性有机化合物(VOC)无空气用作基线和病人的呼吸样本。实际的响应(Δf)单个传感器计算减去基线反应零voc空气从病人呼吸示例响应(抽样)。本事执行阶段之间的基线和取样。QMB5:传感器5。b) Breathprints呼出的空气中得到两个不同的严重哮喘患者:一个不吸烟的病人(圈)和一个吸烟的病人(三角形)。产生breathprints电子鼻平台,结合五种不同以挪士(四个不同的品牌,一个复制的品牌)加起来总共81个传感器的数组。五的81个传感器以挪士(1 - 5中列出一个循环显示,包括:通过对聚合物复合材料,石英晶体微量天平金属卟啉金属氧化物半导体传感器和一场不对称的离子迁移谱仪)。所有传感器的信号已经正常化对任意单位规模介于0(中心)和100(外围)。 The sensor array exhibits differential signals between the two patients, demonstrating two different signatures or “breathprints”. When using adequate training and validation sets eNose signals can be examined for their diagnostic accuracy for (subphenotypes) of disease [144年,145年]。
呼出的气息的gc - ms分析
除了肺癌和其他疾病(149年),gc - ms一直被应用在炎症性肺部疾病的研究,包括哮喘(150年,151年),囊性纤维化152年)和慢性阻塞性肺病(153年]。在分析945种化合物在呼出的气息,总共八个化合物允许92%的正确分类的哮喘和non-asthmatic儿童(150年]。值得注意的是,呼出的挥发性有机化合物的仪器被发现与主要是嗜酸性或中性粒细胞炎症在哮喘和慢性阻塞性肺病154年,155年]。这表明breathomics适合无创性subphenotyping气道炎症性疾病,可能疾病监测。
电子鼻
研究不同的电子鼻传感器系统表明,哮喘患者可以从健康歧视与精度控制在80 - 100%之间(151年,156年]。有趣的是,慢性阻塞性肺病患者也可以歧视从哮喘患者157年证实了),一发现外部验证根据标准指南(158年]。这样确认新招募的病人从不同医院对限制错误发现率[至关重要144年)和验证诊断的准确性(9]。应该强调,观察到的差异在电子鼻breathprints之间哮喘和慢性阻塞性肺病不是由于吸烟习惯的差异,因为哮喘病患者和不吸烟的COPD患者的比较显示相同的差异(157年,158年]。同样,气道阻塞的程度本身似乎并没有影响到电子鼻信号因为breathprints稳定在哮喘急性支气管狭窄和bronchodilation之前和之后159年]。电子鼻系统也已成功应用在研究其他疾病,如肺癌(160年];然而,全面验证这些结果悬而未决。关键的悬而未决的问题在当前电子鼻的研究需要映射(即。进行定量对比设备)(161年)由于传感器不同设备之间的信号是不相同的。
呼出的气息凝结
pH值,测定腺苷和类花生酸EBC提供了有用的信息在哮喘和慢性阻塞性肺病的病理生理过程140年]。最近,蛋白质多路检测已经应用于EBC,显示足够的信号在哮喘患者使用breath-recycling电容器方法(162年]。最具发展潜力的高通量,代谢组学分析EBC通过核磁共振光谱,它是一个强有力的分析技术(163年]。几个独立的实验室最近演示了配置文件EBC的代谢物,为哮喘提供歧视性的信号(35),慢性阻塞性肺病(148年和囊性纤维化137年]。这些研究表明,挥发性和非易失性呼出呼吸代谢组学已经准备好严格的诊断精度的验证。
总结
breathomics的现状是:1)分析仪器对个人识别空气呼出的气体代谢产物(气相)和用于病理生理研究;2)现场验证,便携式以挪士呼吸道疾病的临床诊断和监测正在进行,但尚未敲定;和3)核磁共振光谱学分析流体相EBC的最强大的方法。最近breathomics研究进展包括定制nano-sensor数组的开发特定的疾病实体。此外,第一个研究表明外部诊断准确性的验证以挪士最近出版,同时纵向监测哮喘和慢性阻塞性肺病研究正在进行中。最大的限制使用以挪士差between-device数值数据的可比性。此外,目前,只有一个品牌的电子鼻是商用(Cyranose 320)。这限制了快速进步的多中心研究,但可以克服集中分析multi-eNose平台上运来的呼吸样本解吸管。电子鼻分析在医学的前景被广泛认可。便宜,呼吸在现场、实时分析与在线分析对现有数据库“Breathcloud”是一种可行的诊断评估在低收入国家(前景如。高收入国家(肺结核)以及如。肺癌和哮喘在婴儿)。以挪士的定位在这些领域需要一个最大negative-predictive值(高灵敏度),允许减少和选择性的使用更加昂贵,侵入性和/或危险的诊断程序。
将临床和功能基因组学数据集成到指纹和表型手印
系统生物学
属性定义的一个生物系统不仅是简单的基本功能,但也摆脱其元素之间的交互作用在每一个级别的生物组织(分子、细胞器、细胞、组织和器官)(164年]。推断这些成分之间的相互作用如。基因、蛋白质和配体)和瓦解他们的监管机制是定义涌现性的关键。系统生物学方法的目标是理解整个系统的行为。它们产生令人信服的数学和计算模型的高度复杂的系统组件之间的交互与涌现性(165年,166年]。实现系统生物学方法中遇到的主要挑战是:1)生物系统的复杂性;2)多尺度范围的自然生物信息编码在DNA, RNA,蛋白质,代谢产物和交互网络在不同级别的生物组织(如。在细胞、组织、器官和整个有机体),发生在各种时间尺度;3)所产生的海量数据的组学技术;和4)分散的异构知识。因此,综合系统生物学方法结合实验方法和数学模型和计算方法和模拟分子、亚细胞,细胞和器官水平结构和流程164年]。这种方法提供了更深层次的理解能力中扮演中心角色功能和监管途径复杂生物系统的行为。一个典型工作流程包括:1)数据处理,2)推理网络的代表分子实体之间的关系调查,3)深管理可用的数据和知识,4)仿真系统的行为和5)模型的分析。
处理和初步分析
的典型分析的组学数据集(以下标准质量控制)收益在四个步骤:1)原始信号检测(微阵列杂交,质谱,电子鼻模式、等),2)预处理(减法的背景噪声,平滑、峰值检测,计算水平的表达),3)数据和正常化4)鉴定差异表达基因,肽,代谢物或脂质进行进一步的数据分析,包括特征选择、聚类、分类和通路/网络分析。例如,在U-BIOPRED(无偏预测生物标志物的呼吸道疾病的结果)的项目,一个项目资助的创新药物计划和关注严重的哮喘,科学家发明了一种自动数据分析管道最初lipidomics和蛋白质组学。在通用工作流的每种类型的组学数据需要使用特定的生物信息学工具。转录组是最发达的,以及强大的数据分析建立和管道,其次是蛋白质组学和lipidomics,特定的数据库已经由几个联盟(如。LIPIDMAPS [39,167年,168年])。集成的组学数据需要正常化的数据从不同的平台、数据格式和标识符。这通常是由转换值获得零均值和标准差单位。分析每种类型的组学数据需要特定的选择从广泛的统计,数据挖掘和机器学习技术适用于无偏/偏见,无人监督的监督和uni - /多变量分析。网络连接个人数据读数是适合的工具来表示实体之间的交互,因为他们描述之间的关系(边)的广泛观察到大量元素(节点)169年]。此外,强大的统计和计算技术,如借用图理论,应用于生物网络的分析,如。识别关键蛋白质或主监管机构,即。节点与邻国发生大量的互动。其他主要的方法在一个典型的工作流包括权力和样本大小的计算,特征选择(如。引导、包装)、主成分分析、聚类(如。层次结构、k - means病房,biclustering),和分类(如。支持向量机和贝叶斯网络)。详细描述的优点和局限性的方法及其组合已经超出了本文的范围,但这些方面最近他处(169年,170年]。
Multi-omics集成
识别相似的组学数据可以使用聚类方法(常规和biclustering)和进一步使用网络和通路推理功能分析,表征和分析软件工具(如。创新路径分析(171年]和Cytoscape [172年])。实体之间的因果关系来衡量与“组学技术在不同条件下和/或在不同的时间点可以在概率因果网络模型,利用贝叶斯估计的概率关系范式基于先验知识,或使用互信息(衡量两个变量之间的依赖或互信息量)。这些方法是开发一个单一类型的分析数据(如。转录组基因表达谱),但现在已经扩展到全基因组遗传变异信息集成,dna和蛋白质的相互作用170年]。一个有用的例子是ARACNE(准确的蜂窝网络的重建算法)算法,这是专门设计用于扩大监管网络的复杂性(173年,174年]。尽管大量的数据是由组学方法,数据仍普遍太稀缺而大量可能的交互测试。后果之一是,方法精度往往是模拟数据集上进行了测试,并不能反映真实的生物复杂性,而不是被广泛接受的标准(170年]。这种方法的主要缺点是,它不提供机制和因果关系,必须通过其他方法来解决。深管理不仅依赖的组学数据,也可用与大量的知识集成后的文学和通路数据库管理专家(如。KEGG [175年]),因此可以包括机制和因果关系,使用等标准实现系统生物学标记语言(用)或图形符号系统生物学(SBGN) [176年),和广泛使用的可视化建模工具,如CellDesigner [177年]或Cytoscape [178年]。
通路用于深层内容管理的主要缺点是他们的不准确,不完整,缺乏文档的上下文(如。组织)和所需的大量的时间和专业知识恰当的管理和定期更新。这些问题被自动解决文本挖掘(179年,180年)和社区工作(如。WikiPathways [181年])。动态交互的重要性在时间和空间不是被静态模型生成的数据驱动的概率网络或深的管理。动态模型主要使用普通和偏微分方程,或布尔网络(即。基于逻辑数据类型)的基因调控,尽管校准主要依赖措施获得在体外化验。
数据、信息和知识管理
系统生物学和医学的最终价值是跨平台的组学数据的集成和细胞水平。这就需要有效的知识管理工具和计算平台收集、管理、分析和共享临床和实验数据,将它们集成与先验知识存储在公共数据库(如。PubMed [182年],绑定[183年],Reactome [184年],KEGG [185年])。软件平台的目标是使数据和知识在任何一步的工作流程,提供高互操作性,避免错误处理和分析数据或模型,从而改善和加速全面分析。使用高度异构生物数据集描述格式,术语和数据模式,标准的发展是至关重要的,使他们的综合分析。标准数据管理问题的最小信息(如。最小信息微阵列实验[MIAME] [41]),文件格式(即。应该如何存储的信息,通常是基于xml)和本体(如。基因本体论[转][186年和系统生物学本体(SBO)187年])。需要一个功能接口,它使用户能够浏览、查询和检索信息的基因,蛋白质,脂类代谢产物或通路和网络的兴趣。几个软件平台开发的目的:1)使用电子表格模板的文件一样通过特定的接口来分析软件;2)在线基于维基百科的安全数据和分析工具;3)实验室信息管理系统(LIMS);4)工作流管理系统,如星系(188年基因和康斯坦茨矿工(KNIME[信息]189年]);5)运用190年)和加州大学(191年基因组浏览器。最近的工作包括:1)整合转录组和蛋白质-蛋白质之间的关系如Sage bionetwork倡议;2)开源软件集成等揭路荼联盟和tranSMART平台(192年];和3)商业专有系统从idb (ClinicalSense)、甲骨文(转化研究的解决方案)和以下信息(BioXM)。
tranSMART平台(7,193年)最初是由詹森制药公司研究和开发有效管理知识关联到自己内部的生物标志物的研究。并行是可用的外部研究小组作为一个启用转化研究合作平台。tranSMART让研究团队管理分析结果和病人临床水平,“组学和遗传学生物标志物研究的数据。它使研究人员探索产生不同类型的数据在一个生物标记研究中,生成和测试一种新的假说在研究和探索研究之间的关系。作为一个开放的平台,tranSMART还利用其他开源工具如学术i2b2财团(194年)或统计计算的R项目(195年]。tranSMART现在被几个财团(U-BIOPRED、OncoTrack SAFE-T, PreDiCT-TB, BTCure, eTRIKS, EMIF)支持的创新药物计划(图1)。由以下信息,另外,BioXM已经被用于BioBridge项目的知识管理,研究慢性阻塞性肺病(196年),以及许多其他项目。
复制
这些实验和分析工具使许多分子指纹的识别(145年]。然而,不确定性在他们报道的准确性导致了过于乐观的预期分子资料的预测价值。事实上,只有一小部分报道签名验证,证明是有用的。为多个生物组学数据集的集成水平和数据类型仍然是一个挑战。的确,如此复杂的数据集遭受生物和技术偏见,噪声和错误可能导致假阳性和假阴性的发现。为了克服这些限制,发展的最佳实践和指导原则”omics-based分子资料继续发展(145年]。获得的大量信息和多样性与“组学技术不能作为代理相应的实验设计。首先,一个高效的设计依赖于假设制定、表型定义,权力和样本大小的计算,多个测试校正,复制和实验验证计划(197年- - - - - -204年]。其次,有效的实现需要标准化的实验方法和质量控制程序,数据注释,表示和建模的新算法和数据集成工具。这些措施有助于减少,虽然不能完全消除,潜在的错误和一个合适的平衡之间的敏感性和特异性,从而改善预后和诊断生物标记的准确性。定义配置文件与多种类型的组学数据可能极大地提高其效用。这种策略被应用,例如,在试图整合转录组和蛋白质相互作用网络和/或代谢组学(170年,205年),而第一个综合个人的组学概要文件为单个主题随时间最近报道(206年),支持当前的个人化药物一般趋势。
系统生物学的预测能力
统计分析的组学数据集构成问题,因为大量的功能,他们的数据测量和大量产生。标准统计方法不直接适用不改正错误发现率的多个测试或评估,这是适合个人和独立的生物标记的识别。系统生物学的力量在个人生物标志物是双重的:独立的集成,单一的组学数据集来定义他们的交集和其关注网络相关的元素共同改变与疾病或外部刺激。这减少了病人的数量需要证明治疗的临床表型和效果之间的差别,和现在的策略是成功实现在一些临床研究,如。在呼吸系统174年,207年)、心血管(208年],传染性[209年)和神经系统(210年]疾病以及癌症(211年,212年和肾脏学213年]。
对系统医学的呼吸道疾病
系统生物学方法已经成功地应用于呼吸系统疾病,,例如,暗示,慢性阻塞性肺病骨骼肌变性可能是由于细胞缺氧由于组蛋白修饰符的异常表达与贫穷之间的协调改造的几个组织和能源(207年]。一些大规模的多中心合作项目已经开始开发这种方法破译呼吸道疾病的发展。他们的共同目标是识别小说,复杂的生物标志物的概要文件,结合不同的临床、生物学和功能基因组学数据类型成分子指纹和疾病表型手印。这些新颖的诊断和预后工具旨在提高疾病预防和帮助确定新的更好的药物靶点,个性化治疗(214年]。这样的“系统医学”项目依靠多学科专家的学术研究机构的共同努力下,医院中心,小公司和制药行业,将有助于推进转化医学》(214年]。这些项目中遇到的一个重大挑战是定义最优范围,结合所必需的实验方法和深度提高对疾病及其治疗的理解(如。全部或有针对性的转录组和/或蛋白质组学和代谢组学/ lipidomics)。财务和时间约束是重要因素,更在临床应用的环境和公共卫生。U-BIOPRED [215年),AirPROM(气道疾病预测结果通过特定的计算模型)(216年)和MeDALL(过敏)的发展机制217年)财团以协调的方式实施这项研究战略克服障碍的理解和治疗严重哮喘(U-BIOPRED),慢性阻塞性肺病(AirPROM)和过敏性疾病(MeDALL) [37,218年,219年]。无偏方法最初需要全面的全基因组分析,然后适应具体目标和可用的生物资源。另一个项目,Synergy-COPD [220年),旨在产生一个计算机模型的使用流行病学数据构建的慢性阻塞性肺病的机制,临床试验和医生的采访中,转化为基于模型将有助于复制人体生理学。因此,迭代摄动的生物系统体外和/或在活的有机体内,在网上在大规模试验中产生,然后完善综合表型手印前景的深入了解,呼吸道和其它复杂的慢性疾病的诊断和治疗(214年]。
结束语
使用“组学方法来阐明疾病机制近年来呈指数级增长,由显著改进分析平台,提高分辨率和灵敏度以及提高吞吐量和降低成本。派拉蒙,充分利用生成的海量数据的组学方法创建适当的知识管理和数据处理平台,加上明智地应用生物信息学,统计和建模工具。同样重要的是要承认“omics-based测试,包括预后和诊断工具基于变量的变化模式,非常容易出错,需要严格的统计处理。医学研究所推荐的,“所有的信息需要验证测试发现过程通过出版物或披露专利申请”和“计算过程必须“锁定”(记录和不再改变了),然后用一套新的样品确认不习惯在最初发现”(221年]。利用系统生物学分析的组学数据提供了重大挑战,并将必须遵循类似的规则,正确描述研究这样的大型数据集可以被设计成具有足够的力量,利用降维提出的网络模块在生物标志物发现过程的识别。
所有这些功能分层医学翻译尚未发生,需要大协作交付的帮助下的产业合作不仅计划基金项目,还汇集了相当多的专业知识存在于学术界和制药行业。虽然有挑战,这些新的操作模式,尤其是他们的复杂性,希望这样的全球疾病的系统性方法,结合良好的还原论者/中心集中方法,现代科学的发展,会导致疾病的范式转换描述。最后应该强调的质量数据生成的组学方法是高度依赖于临床表现型的受试者的质量,进一步强调严格的表现型的重要性。最终,真正的考验将是证明这种综合方法提供新的见解疾病机制,加快药物研发进程,使早期的疾病检测。因此,新生的系统医学领域需要证明其能力在临床和实验室兑现其承诺的临床研究的范式转向大规模的生物学检测方法,发现理解,治疗,最终,治疗和预防疾病。
脚注
支持声明:这项工作是支持的U-BIOPRED财团(无偏预测生物标志物的呼吸道疾病的结果,格兰特协议IMI No.115010)。美国Ballereau和c . Auffray也FP7-MeDALL财团支持的(机制发展的过敏,格兰特协议FP7 No.264357之下)。
利益冲突:披露可以找到与本文的在线版本www.www.qdcxjkg.com
- 收到了2012年5月16日。
- 接受2012年12月14日。
- ©2013人队
引用
- ↵
- ↵
-
- ↵
- ↵
- ↵
- ↵
- ↵
-
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵
- ↵











![Flowchart of the ’omics-based workflow for unbiased clinical biomarker discovery employed in the U-BIOPRED project that employs tranSMART as its knowledge management platform [7].](http://www.qdcxjkg.com/content/erj/42/3/802/F1.large.jpg?width=800&height=600&carousel=1){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Analysis of human induced sputum analysed using the label-free approach, LC-MSE, Silva et al. [74]. a) The obtained LC-ion chromatogram of peptides measured in sputum and b) an MS/MS spectrum of a peptide ([M+H]2+ m/z = 1185.68) identified from lipocalin-1.](http://www.qdcxjkg.com/content/erj/42/3/802/F3.large.jpg?width=800&height=600&carousel=1){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Breathprints of eNoses. a) A typical breathprint from a patient with asthma obtained with a non-commercial eNose consisting of eight quartz microbalance (QMB) gas sensors coated by molecular films of metalloporphyrins. Deflections represent the response (change in sensor frequency) to volatile organic compound (VOC)-free air used as a baseline and the patient breath sample. The actual response (Δf) for individual sensors is calculated by subtracting baseline response to VOC-free air from patient breath sample response (sampling). A wash-out phase is performed between baseline and sampling. QMB5: sensor 5. b) Breathprints of exhaled air as obtained in two different patients with severe asthma: one nonsmoking patient (circles) and one smoking patient (triangles). The breathprints are generated by an eNose platform, combining five different eNoses (four different brands, one duplicated brand) adding up to an array of 81 sensors in total. The 81 sensors from the five eNoses (1–5 are listed in a circular display, comprising: carbon-black polymer composite, quartz crystal microbalance metalloporphyrin, metal oxide semiconductor sensors and a field asymmetric ion mobility spectrometer). The signals from all sensors have been normalised towards an arbitrary unit at a scale between 0 (centre) and 100 (outer circle). The sensor array exhibits differential signals between the two patients, demonstrating two different signatures or “breathprints”. When using adequate training and validation sets eNose signals can be examined for their diagnostic accuracy for (subphenotypes) of disease [144, 145].](http://www.qdcxjkg.com/content/erj/42/3/802/F5.large.jpg?width=800&height=600&carousel=1){kind=link}
{kind=link}