





摘要
随着研究人员认识到需要大量样本来确定对复杂疾病易感性的遗传基础,基因生物库研究正变得越来越普遍。在本综述中,作者简要概述了实施这样一个大规模项目时应该考虑的一些问题,从研究设计到样本管理、数据编码和存储到统计分析和公众参与。这些问题的具体解决方案在“苏格兰一代”项目中得到了实施,但概述的一般原则与任何生物银行研究都相关。
系列“阻塞性睡眠呼吸暂停症的遗传和心血管综合征”
由R.L. Riha和W.T. McNicholas编辑
本系列中的1号
几种常见的复杂疾病的易感性与遗传因素有关1.这些疾病可能有几个相互作用的遗传风险因素和环境,因为单个风险因素的边际效应很小,需要大样本来检测。这在一定程度上导致了大规模生物库项目的发展,这些项目试图定位和确定疾病易感性的基因影响2.在目前的回顾中,作者概述了一些原则,在设计和实施这样一个项目时要考虑,并举例说明了Generation Scotland (GS)。GS是苏格兰大学医学院、国家电子科学中心(英国爱丁堡和格拉斯哥)、苏格兰初级保健学院(英国邓迪)、英国医学研究委员会在苏格兰的单位和国家卫生服务(NHS)的信息服务处(ISD)苏格兰国家服务(爱丁堡)。苏格兰家庭健康研究目前包括四个补充项目:苏格兰家庭健康研究3.《21世纪的遗传健康》、《供体DNA数据库》和《对抗慢性病的生物标记物》等。这些项目将招募超过50,000名个人和家庭成员(约占苏格兰人口的1%)进行基因分析,并将建立有利于未来研究的流行病学、统计和信息基础设施。为了实现这一目标,GS执行协议来收集与常见疾病相关的详细表型,包括心血管疾病、糖尿病、肥胖和精神健康障碍。用于研究目的的生命过程中的健康发展(通过电子记录追踪)也需要获得同意。并收集了数量性状数据3..当前综述中的实现是在GS项目的背景下提出的,但一般原则可以应用于任何生物银行研究。
研究设计
学习设计将由感兴趣的表型/疾病决定,以及对研究人员提供的人口和资源。服用阻塞性睡眠呼吸暂停/低钠肿瘤综合征(OSAH)作为具有复杂性疾病的常见疾病的例子,家庭,双胞胎和联系研究的古典方法已经发现了约40%的特质变异,归因于遗传因素4.,一级亲属的相对风险为1.9 ~ 2.05..然而,这些研究由于缺乏对OSAHS的精确描述,以及用于量化呼吸中断的测量方法的可变性而受到阻碍。对OSAHS的全基因组扫描显示其与基因组的几个区域有关联6.,暗示了多种遗传因素的影响。一些研究还关注中间表型,如肥胖7.,这本身就是复杂的特征。协会研究提供了有关奥沙漠发病机制的更多信息8.,但进一步的研究是确认这些结果的必要条件。分类的积极协会(如。疾病状态)特征代表了病例组和对照组之间等位基因频率的显著差异。理想情况下,这将反映单核苷酸多态性(SNP)通过蛋白质序列或调控元件的改变对疾病易感性的直接影响,但更可能反映的是一种间接关联:强连锁不平衡(LD)中的SNP与致病SNP。LD是对不同基因座等位基因之间相关性的衡量,并构成了HapMap项目的基础9.通过量化数千SNP之间的LD和构建常见单倍型的地图来对人类基因组目录。在确定特定调查中的基因型中的标记时需要考虑测试群体中的LD水平。
基于人群的关联研究存在虚假关联的风险,这种虚假关联可能会从看不见的群体结构或混合中产生假阳性结果:如果样本群体包含两个或多个等位基因频率和疾病流行率不同的亚群体,就可能发生混淆。一项设计良好的研究将通过根据种族匹配病例/对照组或纠正观察到的结构,将这种影响最小化。对抗伪关联的方法包括基因组控制10,它使用非关联标记来量化检验统计数据的膨胀并相应地调整它,或结构化关联方法11,它将个体概率地分配到一个亚群体中,并测量这些群体之间的关联。采用以家庭为基础的控制,通过建立不受人口结构影响的测试,消除了对这种方法的需要。传输不平衡检验(TDT)12当标记和疾病状态之间的任何关联是由真正的连锁而不是种群结构引起时,返回阳性结果。TDT最初是通过比较杂合子父母遗传给受影响后代的等位基因的频率与其孟德尔期望的频率而建立的,任何显著偏差表明性状与标记之间存在连锁和关联。这避免了分层的问题,因为对照组由家庭内未传播的等位基因组成,并且已经实施了对基本TDT的若干扩展。基本的理论形成了一个更一般的基于家庭的关联测试的基础13,这还基于遗传和表型残留物之间的协方差构建测试统计,但允许更广泛的模型,在一次测试中包含多个性状和任意家庭结构。在SFHS中收集的基于家庭的数据将良好地对待这些基于家庭的研究,以及利用家庭研究的其他优势14.
订婚
在任何生物样本库研究中,与公众和患者的接触都是必不可少的,以鼓励感兴趣的社区的参与,并在这些社区和科学家之间产生信任。这是GS在其早期阶段的综合考虑,在样本收集之前,由专门的研究团队调查研究的伦理、法律和社会方面。咨询最初包括对焦点小组进行审查和访谈15通过与公民团体的对话,与家庭成员的访谈,以及参与者在就诊后完成的退出问卷,这些都在进行中。这些过程在GS网站的咨询页面上有更详细的概述16.研究人员和社区之间的信任也可以通过利用初级保健专家作为项目和社区之间的中间人来促进17.SFHS系列最初通过一般实践名单招聘,允许志愿者与可信专业人员之间的互动。
生物银行项目之间的参与也是可取的。基因组学公共人口项目(P3G)18是一个国际联盟,旨在促进生物样本库之间的科学合作,促进不同项目之间的协调,使数据得以合并。GS是P3G和其他几个生物银行项目的创始成员,致力于在收集的数据方面实现项目之间的共性。
样品收集
Biobanks可以从多个位置收集样本并在不同的实验室中处理它们。这提高了数据集成的问题,GS开发了用于自动收集表型数据的定制方法以补充其他IT系统。这允许开发联动和集成机制,使研究人员能够访问在分散模型中保持的敏感数据,别名以确保匿名。该系统的关键是由邓迪大学(邓迪,英国)开发的志愿者管理服务(VMS)和约会服务(AP)。前者设法志愿者身份和联系人管理,而后者则管理诊所预约身份。爱丁堡大学(英国爱丁堡,英国)GS团队开发了一种互补的灵活性表型收集方式,允许在研究参与者与数据采集过程的互动过程中允许可靠的数据收集(图1⇓).该系统与VMS/APS集成,在为研究人员提供瞬态标识数据的同时保持匿名,确保有效性。通过为每个参与者使用唯一的样本id来保持匿名性:GS标签以人类可读的条码格式包含样本id,并用于与参与者相关的所有试管和文件,包括适合冷冻的冷冻标签。当样品在实验室接收时,可将样品条形码直接扫描到样品库存软件中,减少用户输入错误。
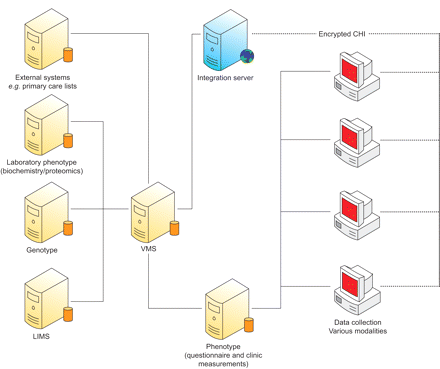
发电苏格兰数据采集(表型)背后的信息技术示意图:21世纪和捐赠者DNA数据库的遗传健康。Chi:社区健康指数;VMS:志愿者管理服务;LIMS:实验室信息管理系统。数据库服务器以黄色,Web服务器为蓝色,桌面或笔记本电脑以红色表示。
实验室样品管理
实验室在成功实施遗传研究方面发挥着关键作用。在基于统计指南的研究设计过程中,还应考虑待收集的必要生物样本,以及提取和储存的方法。静脉血是一种方便的DNA来源,但有用的量可以从唾液/漱口水的侵入方法较少19.血清、血浆和尿液可以测量生化和蛋白质组表型,这可以丰富遗传学研究。所有样品都有很高的内在价值,如果放错地方或储存不当,可能会导致延迟和增加成本。在GS中,这个问题已经通过实现一个实验室信息管理系统(LIMS)来解决。
GS LIMS供应商Starlims (Hollywood, FL, USA)在经过竞争性招标过程后被选中,由此产生的LIMS提供了一种系统的样本存储、管理和跟踪方法。在苏格兰各地收集的样本通过远程访问爱丁堡的一台服务器,在客户电脑上登记,并分配存储在冷藏室和罐中,并在入口验证数据。所有参与该项目的实验室使用相同的样品报名表(图2)⇓),由于这一过程的标准化,便于根据同一协议在多个地点管理样品。每个领域都有验证,以最大限度地减少数据输入错误,样品只有在实验室出现时才登记到LIMS。此外,样本可以编辑、发送给其他研究人员或删除,所有这些都带有研究管理和研究治理所需的审计跟踪。
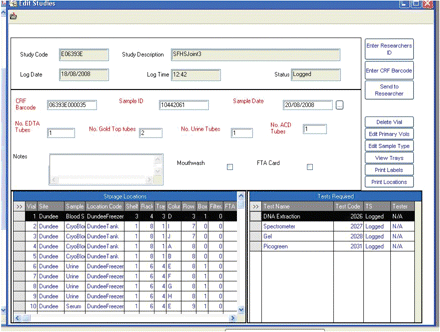
实验室信息管理系统样品输入表格显示的存储位置。
LIMS还允许样本安全地从一个实验室运到另一个实验室。例如,每500个批次的9毫升血液样本被送往爱丁堡用于DNA提取,含有用于基因分型的DNA工作样本的微量滴定板被送回最初的实验室。通过LIMS进行平板管理对于跟踪DNA存储解决方案和帮助后续数据管理,特别是基因分型至关重要。通过LIMS编制用于实验分析的稀释工作DNA的平板,消除了样本id的转录错误,并通过扫描其条形码标签来显示平板的内容。通过访问政策,只有通过LIMS访问的认可实验室才允许接收GS DNA板,允许详细跟踪资源和维持高标准的实验室实践,无论实验程序是内部或外部委托。LIMS的各种规则、验证和报告功能在GS内优化生物资源的质量管理中发挥着重要作用。定制LIMS的实现可能不是每个实验室都能轻易获得的,但是其他样品库存软件可以以较低的成本以现成的软件包在商业上获得。随着相关开源软件的出现20.,可以使用较少的简化系统应用良好的样本管理的基本原则。
数据编码与管理
参与者招聘开始前的数据编码,收购和存储方法的考虑将导致具有更可靠数据的研究,并允许轻松实施后续研究一旦到位。对表型数据的验证对于研究的完整性和下游分析的疗效至关重要。GS数据在进入时的研究诊所验证通过在笔记本电脑或PC上形成,提高准确性和完整性。系统应用两套限制:“硬限制”,其中排除了物理上不可能的值,以及“软限制”,要求用户验证。这些限制由临床团队决定,并在数据字典中设置,如果测量值源于指定的限制,则返回错误消息。Table 1⇓显示血压测量的限制集,可以调整到测量时考虑生理状态,如。睡眠,压力,手术后。这使得在收集点上获得的数据尽可能没有错误,从而最大限度地减少下游问题。
GS表型收集是整个基础设施的一个子系统,只处理来自志愿者的数据,通过分配给每个诊所就诊的条形码进行参考。VMS还可以访问NHS苏格兰社区健康指数,通过志愿者唯一标识符的加密版本,允许表型与医疗保健数据相关联。该系统提供了可靠的数据集,可最大限度地减少统一问题,并具有许多实时工具,允许学习管理者实时监测问卷和人口采样的内部验证的性能。这允许精细调整问卷和研究志愿者配置文件,并监测研究诊所数据采集人员的准确性和效率。
在进行统计分析之前,必须对原始数据进行编码。对响应进行编码的问题可能会导致分析困难,因此应该考虑问题的有效性:需要解释自由文本,这可能会引入错误,因此应尽可能对响应进行预编码。在设计编码方案时,必须考虑数据的最终使用,因为公布的标准可能不足以充分描述特定研究中的数据,因为这些系统往往是在一组可能不适用于此类研究的参数内创建的。例如,英国的NHS编码系统通常反映的是操作边界,而不是种族或政治边界(表2)⇓),种族分类没有区分威尔士(凯尔特)和英语(盎格鲁-撒克逊)群体,但这样的准确性可能在群体遗传学研究中很重要。因此,NHS/ISD对“其他英国人”的分类可能需要细分为威尔士人和英格兰人。这些组可以重新组合,与公布的NHS数据进行比较。
如果一项研究需要与其他数据集集成,使用相同的或现有编码系统的子集将最小化协调问题。否则,将需要创建映射表,但映射表并不总是给出精确的对应,可能导致数据丢失。如果需要在来自两个或多个项目的数据之间进行链接,那么这些数据应该以类似的形式保存。主要标识符的数字和文本代码之间的转换错误可能会妨碍准确的链接,虽然概率记录链接会有所帮助,但事先计划将大大提高成功。如果没有计划与其他研究进行比较,那么度量就不需要符合标准,可以纯粹是内部的,但是一旦比较变得重要,就需要考虑这些标准和互操作性。
数据收集,存储和分析
在分析继续之前,需要在多种模式中收集的数据。在GS中,这些模式包括基于Web的表单,可将编码数据直接发送到数据库中,以及可以在数据库中提供的Windows窗体通过一个合适的网络连接。所有的收集方式都使用条形码将数据传递到中心表现型数据库,在那里使用预定义的查找表进行编码。
GS信息基础设施提供了安全的数据资源,以支持GS项目的数据需求。服务器在防火墙之后得到保护,所有数据存储库都放置在带有raid驱动器的镜像服务器上,确保使用离线网络附加存储和本地磁带维护最大的数据冗余和备份。所有服务器都位于安全管理的环境中,没有公共访问,并连接不间断电源,以确保在停电时顺利关闭。
进行的具体分析将取决于收集的表型,如在最初的研究设计中所考虑的。例如,一个双等位SNP有三种可能的基因型,可以存储为一个简单的分类变量,用于关联研究,或作为计数次要等位基因拷贝数的序数变量,用于,例如,逻辑回归或得分测试21.在定义用于收集数据的类时必须小心,如表2中的种族例子所示⇑和疾病特征,其中精确的表型定义也很重要,特别是如果来自多个研究的数据要结合。
连续特征可以从诊所直接读取到数据库中,允许即时验证,以及快速访问数据。在经典的数量性状位点(QTL)分析中,这些性状可以作为表型本身进行分析,也可以作为导致疾病风险的危险因素/协变量。QTL分析试图将总性状变异的一部分归因于遗传效应,并确定导致该变异的位点。在更复杂的疾病易感性的模型,一般线性模型可以评价标记基因型效应的意义,同时允许其他协变量遗传和环境的影响考虑在内,例如,高血压患心脏病的风险。全基因组扫描产生的大量数据进一步提出了需要考虑的统计和计算问题。
释放资源和返回数据
为了最大限度地利用任何生物样本库的资源,重要的是要为具有核心团队以外领域专业知识的研究人员提供样本和数据。许多GS科学家已经在致力于确定苏格兰人口的致病原因,但有规定可以向来自学术或商业组织的外部研究人员提供数据。重要的是,制药公司能够获得资源,以便研究潜在的新药和治疗方法,而生物样本库只能与行业合作来做到这一点。关于可用资源的详细描述可以在GS网站上找到22.
在制作资源之前,必须有明确的规则,可以控制如何使用样本和数据。GS规则包含在GS网站上的第一个工作版本中的管理,访问和出版物策略中。这是目前正在协商的,反馈从潜在的用户和其他有关方面欢迎。该策略解释了用于管理访问权限和从GS资源的数据的访问和发布数据的GS程序,并用于指导资源管理和开发委员会。在签署数据或物料转移协议的时间为12个月后,使用GS资源,协作者必须返回其分析中使用的最终数据集的副本以及这些变量的导出变量和描述。管理,获取和出版物政策的整体目的是确保所有申请都与GS的核心目标保持一致,并遵守其道德标准和关于参与者机密的严格规则。
结论
在复杂性状的遗传分析中,良好的样本和数据管理是必要的,以确保数据准确而有效地从诊所收集到最终将进行分析的研究人员。本文概述了这类项目可能遇到的一些问题,以及一些可以用来克服与“苏格兰一代”有关的问题的原则。复杂的疾病易感性受到许多影响小的基因的影响,检测这些基因需要大量的基于人群的样本。对于如此庞大的样本,高效的样本存储和管理是非常重要的。同样,为了确保能够得出有效的结论,需要对遗传数据进行良好的管理,并仔细收集、编码和验证准确的表型数据。这些问题需要临床医生、研究人员和信息技术人员之间的密切合作,因为理想情况下,基础设施应该在任何数据收集之前就位,而且随着基因研究的规模和范围的增加,基础设施将变得越来越重要。
兴趣表
没有宣布。
致谢
新一代苏格兰科学委员会及其附属机构的正式成员为:L. Hocking, G. Murray, E. Rattray, D. Reid, B. Smith, D. St Clair和L. Stott,均为阿伯丁大学(英国阿伯丁);J. Berg, G. Findlay, C. Jackson, K. Matthews, M.M. McGilchrist, ad . Morris, C. Palmer, F. Sullivan和R. Wolf,所有邓迪大学(邓迪,英国);D. Blackwood, H. Campbell, S. Cunningham-Burley, I. Deary, G. Haddow, S.M. Kerr, P. Linksted, P. McKeigue, D. MacIntyre, R. Morton, W. Muir, D.J. Porteous, S. Ralston, J. Ure and A. Wright, all University of Edinburgh (Edinburgh, UK);J. Cavanagh, J. Connell, M. Connor, A. Dominiczak, P. Ellis, B. Fitzpatrick, I. Ford, R. Gertz, P. Johnson, R. Lindsay, J. Pell和G. Watt,所有格拉斯哥大学(英国格拉斯哥);A. Philp和M. Sweetland,国家卫生服务体系(NHS)苏格兰国家服务体系(爱丁堡);和R.O. Sinnott,国家科学中心(格拉斯哥)。作者非常感谢所有参与者和整个Generation Scotland团队,包括面试官、计算机和实验室技术人员、文职人员、研究科学家、志愿者、经理、接待员和护士。苏格兰政府首席科学家办公室和苏格兰基金委员会为“苏格兰一代”提供核心支持。
脚注
编辑评论请参阅第233页。
通过回答有关本文的问题,获得CME认证。您将在此问题的印刷副本的背面找到这些或在线www.www.qdcxjkg.com/current.shtml
- 收到了2008年3月20日。
- 公认2008年10月15日。
- ©ers Journals Ltd











{kind=link}
{kind=link}
{kind=link}
{kind=link}