


缺失的数据是一个经常遇到的问题在流行病学和临床研究。1,2一种方法是包括在分析只有那些参与者没有失踪的观察(完整或可用的案例分析)。1- - - - - -4然而,除了减少统计力量,这种方法往往会导致偏见的估计协变量和结果之间的关系。2,3,5,6另一个流行的方法是使用归责方法来代替缺失值。2同样可以应用这些方法对缺失的结果,失踪的曝光和失踪的协变量。missing-indicator方法,第三种方法是专门为失踪的“数据提出病因学的研究。7,8这种方法使用一个虚拟(1/0)变量的统计模型来表示该变量的值是否丢失,和所有缺失的值设置为相同的值。因此,每个参与者仍然可以包含在分析,减少损失的统计力量。
在2005年和2006年,missing-indicator方法发表两篇论文,相互矛盾的结论。3,4Donders和同事关注失踪在非随机研究和协变量数据认为missing-indicator方法很可能产生偏见的结果。3偏差的方向和大小取决于missingness的原因或机理。相反,白色和汤普森关注失踪基线协变量数据的随机试验,发现missing-indicator产生无偏估计方法的治疗效果。4
鉴于missing-indicator的流行方法在医学研究人员,我们的目标是阐明这种明显的差异。我们回顾missing-indicator方法和说明其有效性,使用真实的数据和不完整的协变量的随机和非随机研究。
方法来处理缺失数据协变量
完整的案例分析
处理缺失的协变量数据的最简单的方法是分析参与者的省略与任何缺失的数据(即。,只执行一个分析可用的或完整的数据)。虽然这导致损失的统计力量,完成案例分析通常为无偏估计当参与者没有完整的观测是研究人群的代表性的子集,这种情况被称为“完全随机缺失。”2,3,5然而,通常不太可能丢失数据完全随机的,而是missingness数据(部分)取决于观察病人的特点。诊断准确性,例如,在研究信息入侵测试可以丢失如果诊断基于前已经足够清晰(微创)测试。在这种情况下,完成案例分析可能导致偏见的估计。
完整的案例分析无偏只有missingness是条件独立的结果,9,10这意味着其他病人变量,missingness无关的结果。这是不太可能在给定的例子。
归责
如果missingness变量与观测到的特征而不是未被注意的特点,数据(混淆)被称为“随机缺失”。2,5,6如果随机丢失的数据,可以使用观测数据估计缺失值,随后取代(转嫁)估计缺失值。这通常是通过使用多变量回归模型,而背景的缺失值最可能的值,根据所有观察到的病人的特征,包括结果。11在多个归责、不确定性估算值的事实并不是实际的观察,而是估计占。2,3,5,6,9多重填补方式提供了有效的估计和标准错误在很多情况下随机缺失的数据丢失。2,3,5,6,11然而,它是一个复杂的技术要求专业知识和适当的软件。2因此,简单的方法,比如missing-indicator方法,更有吸引力。
Missing-indicator方法
失踪的“数据missing-indicator方法提出了病因学的研究7,8和医学文献中已经得到太多的关注。3- - - - - -6,10,12missing-indicator法并不归咎于缺失值。相反,失踪的观察设置为一个固定值(通常为零,但其他数字会给相同的结果),和一个额外的指标或假(1/0)变量添加到分析(多变量)模型来表示该变量的值是否失踪。因此,每个参与者仍然可以被包括在维护统计分析能力。
当使用missing-indicator方法调整为一个不完整的协变量,自变量之间的估计协会正在研究(例如,治疗,风险因素或预测)和结果是两个协会代表的加权平均(a)自变量和结果之间的关系,对所有协变量调整后,在参与者来说,所有数据被观察到;和(b)自变量之间的关系和结果,调整只是为了完成,在参与者来说,协变量没有被观察到。第二个非随机研究协会通常是有偏见的,因为只有部分调整了混杂。此外,第一个协会是一个完整的案例分析的基础上,这个协会是无偏只有missingness是条件独立的结果。9,10但是,鉴于非随机研究的本质,反是通常互相相关,missing-indicator方法几乎总是会给偏见的结果。3
然而,在随机试验,随机化意味着基线则反是平衡在治疗组,因此没有待遇相关研究。因此,未经调整的随机试验的治疗效果是公正的。因为随机化,缺失值的分布可能是平衡在治疗组。因此,两个参与者之间的治疗和结果之间的联系为谁所有数据观察,以及治疗和预后之间的关系参与者来说,并非所有的数据观察,将无偏。9因此,完整的案例分析和missing-indicator方法将无偏估计。在连续试验结果,协变量调整的主要原因是提高精度。一个重要的问题,无论missingness的比例,包括所有参与者进行分析估算意向处理效果至关重要。因此,使用missing-indicator方法估计得到的将比获得更精确完整的案例分析,4他们还将遵守意向处理原则,包括所有参与者随机分配到治疗组。13
Missingness基线协变量的随机试验不一定是相同的失踪完全随机。在一个随机试验的影响一定治疗抑郁症,患有严重抑郁症的参与者更有可能会丢失的协变量基线。如果基线协变量表明抑郁症的严重程度,然而,missingness可能也依赖于基线变量本身的值,叫做“失踪不是随意。”4但是,即使基线协变量数据丢失不随机,随机化意味着missingness仍不相关的治疗,因此,观察治疗效果仍将是公正的,missing-indicator方法的应用。
我们已经表明,设计的研究,而不是missingness机制,确定missing-indicator方法处理缺失数据是有效的。详细解释偏见当使用missing-indicator方法在附录1(可提供www.cmaj.ca /查找/ 5 / doi: 10.1503 / cmaj.110977 /——/ DC1)。
例子
在本节中,我们说明的利弊missing-indicator方法使用两个案例研究。在两个例子中,我们从一个完整的数据集。这些完整的数据集的结果被认为是真正的联系。新创建的结果数据是使用真实的关联。Missingness当时使用指定创建机制,三种方法来处理缺失数据应用:missing-indicator方法,完整的案例分析和多重填补方式。我们关注的情况下只有一个协变量与缺失值。方法将很可能差异更明显当多个协变量缺失值。所有分析R为Windows(2.8.1发布版)14或占据(11)版本。多重填补方式使用多重填补方式实现了链方程R15和占据。16整个过程(创建缺失的值和处理缺失值的三种方法分析)重复了1000次减少随机变化。1000复制的选择可能会意味着“正确”95%的覆盖率在93.6%和96.4%之间。
示例1:诊断研究
在一项研究中涉及成人在深静脉血栓形成被怀疑谁,几个指标测试评估的诊断价值。17795名参与者的可用数据集包含两个指数的测试来预测深静脉血栓形成的存在与否:小腿周长差至少3厘米(yes / no)和等离子体d二聚体的水平(连续,对数转换)。这两个指数之间的皮尔逊相关测试为0.32(95%置信区间0.25 - -0.38)。
我们创造了25%的缺失值的变量d二聚体的水平在一个随机样本研究的人口失踪(完全随机),或与相关missingness小腿围和深静脉血栓形成(随机缺失)。在后一种情况下,missingness的概率d二聚体水平翻了一番如果参与者有很大差异在小腿周长与深静脉血栓形成或一个小小腿周长差没有深静脉血栓形成。这个选择与临床实践,因为在一个“正常”的小腿周长的实例结合“健康”临床表现(低概率的深静脉血栓形成),额外的测量d二聚体的水平可能省略。或者,一个很大的区别在小腿周长与深静脉血栓形成的临床表现可能直接导致推荐参考测试(超声)和跳过d二聚体测量。
多个归咎我们使用预测意味着匹配一分为二的小腿围和深静脉血栓形成的不同状态中线性回归归责模式,和25估算数据集。18我们分析每个估算数据集上使用逻辑回归的深静脉血栓形成状态日志d二聚体的水平和小腿周长一分为二的区别。我们结合估计回归系数及其标准错误之前使用标准程序呈现优势比。18
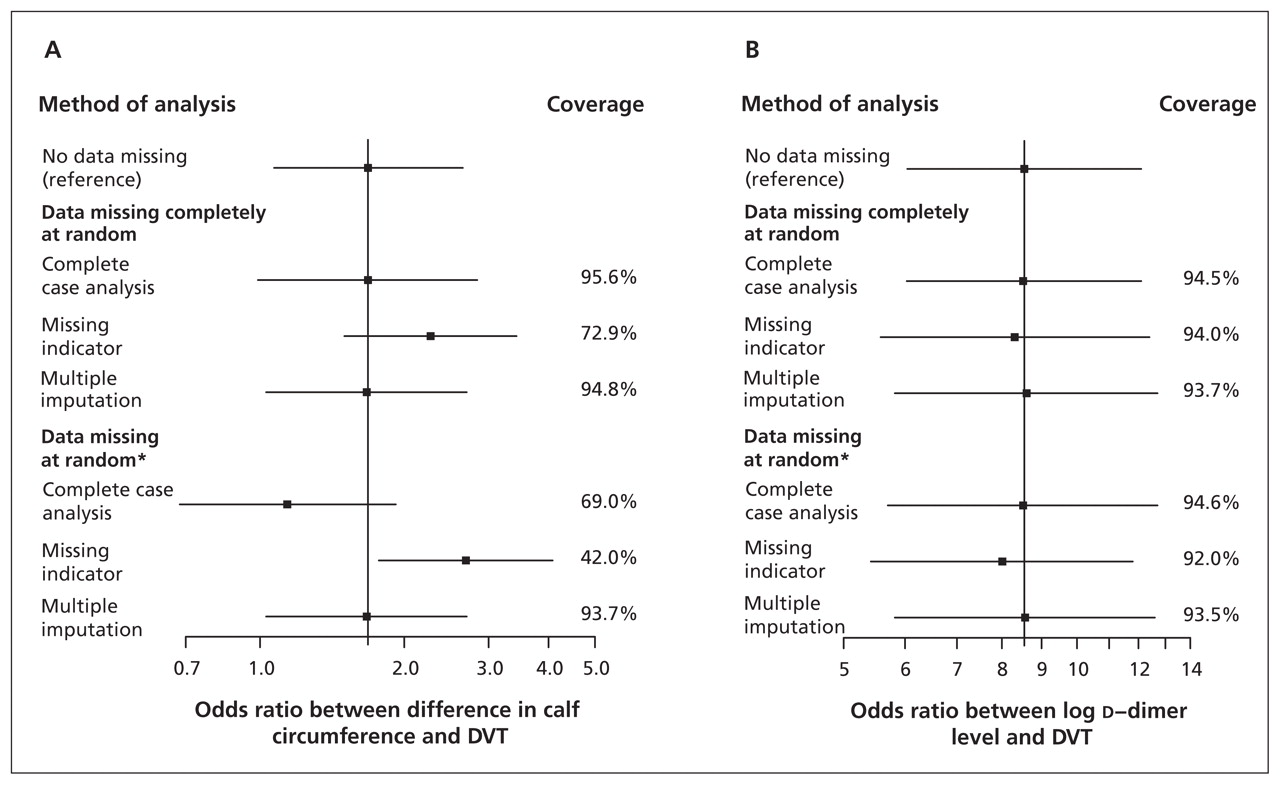
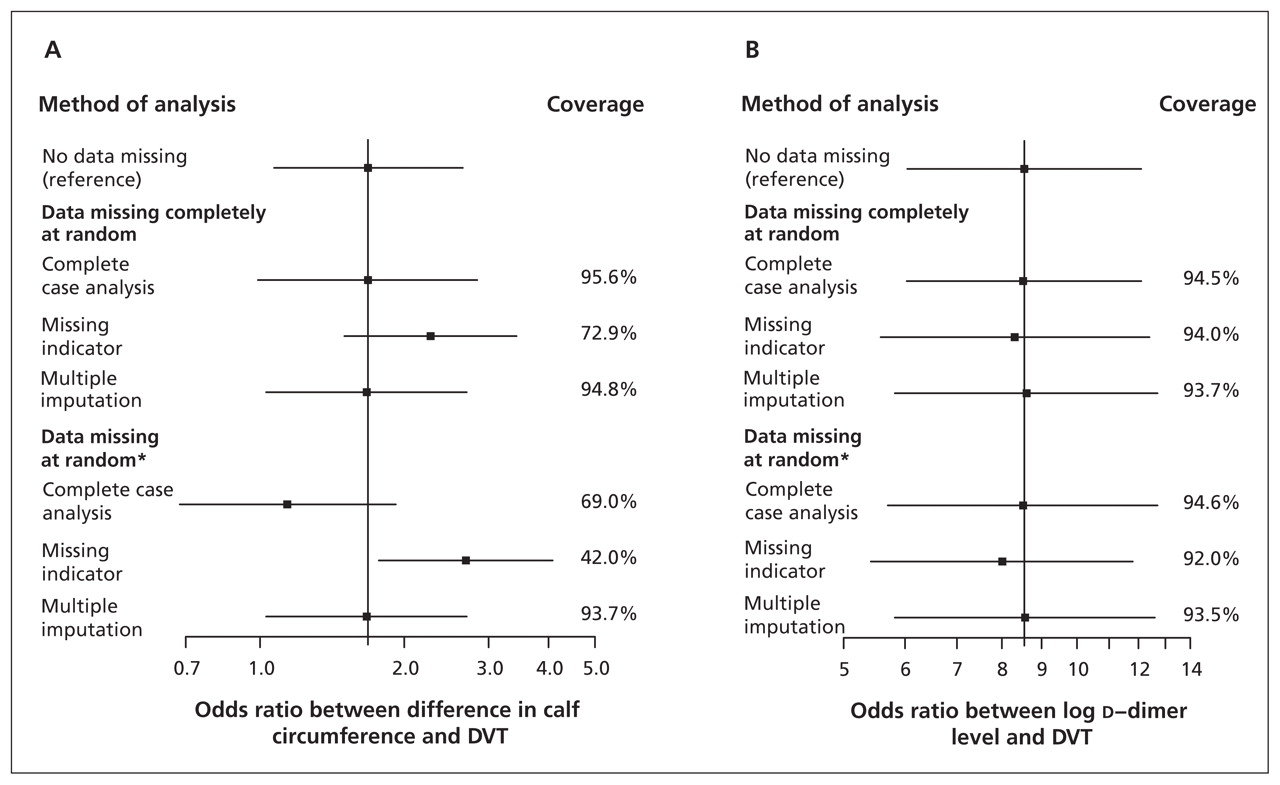
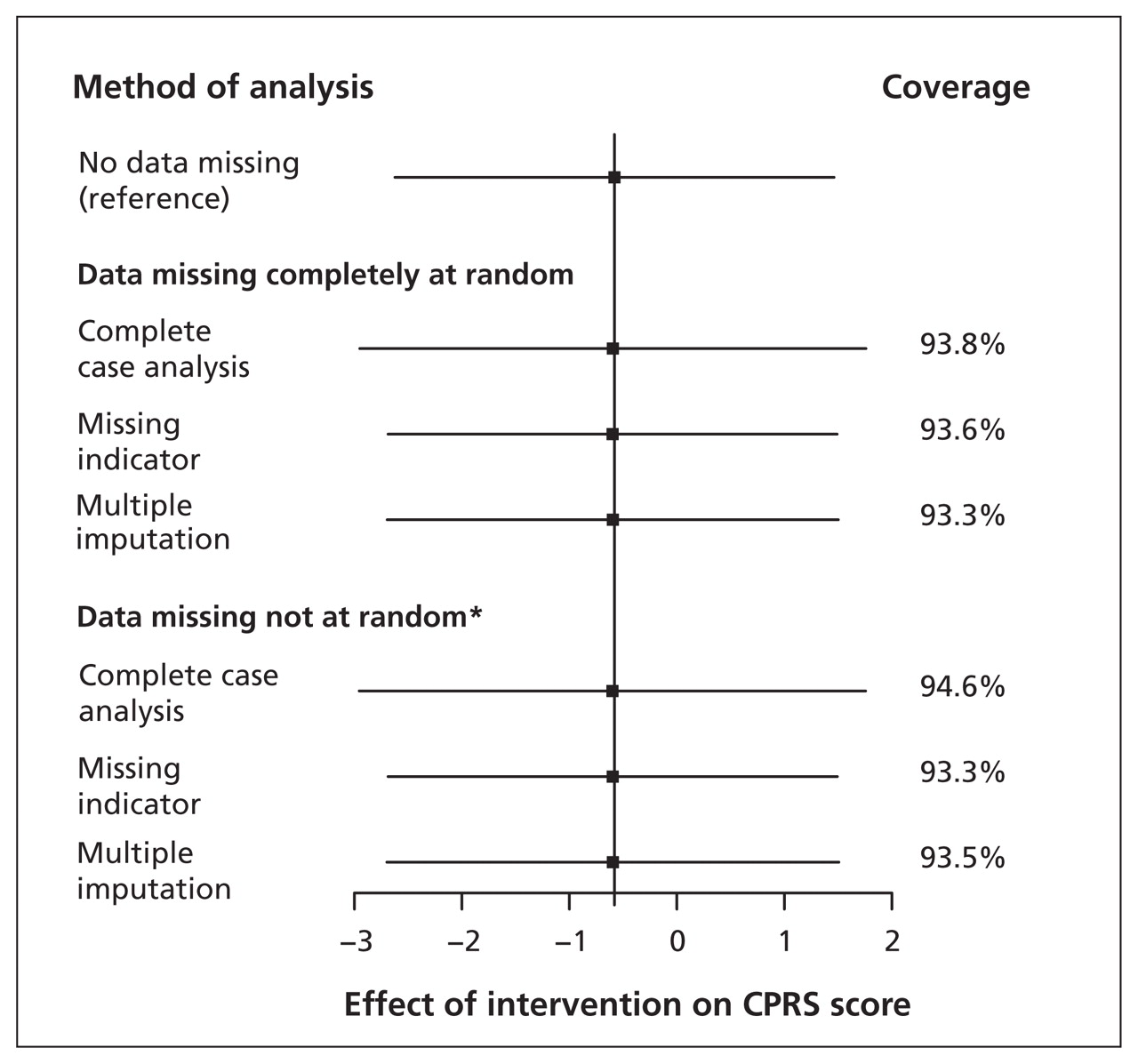
使用missing-indicator方法导致偏见小腿围和结果之间的联系是否missingness失踪了完全随机随机或丢失(图1一个)。完整的案例分析提供正确的估计之间的关系指数的测试和结果,和覆盖率接近理想的95%当数据失踪完全随机。然而,结果与其他方法相比更少的精确置信区间(大),因为更少的参与者包括在分析中。完成案例分析产生偏差估计小腿周长missingness随机丢失的时候。最后,多个归咎为无偏估计提供了良好的覆盖无论数据随机失踪或完全随机。missingness的比例增加时,方法之间的差异变得更大(结果未显示),如图所示。19观测变量之间的关系与缺失的值(d二聚体的水平)和结果(深静脉血栓形成)显然是公正的(图1 b)表明,使用missing-indicator方法主要为一个变量影响其他变量的系数。
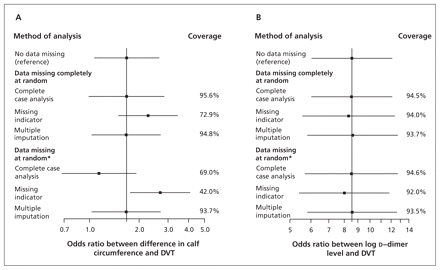
比较的分析方法(完整的案例分析,缺少指标,多个归责)来处理缺失数据在两个指数的诊断研究测试——在小腿周长(a)和差异d(B) -二聚体水平与缺失的数据在一个诊断预测。更多细节请参见示例1。深静脉血栓形成深静脉血栓形成。
注意:优势比(ORs)和95%置信区间(CIs)是基于对数转换口服补液盐和标准错误,平均1000多模拟,除了参考方法,分析引起完全观测数据集。报道表明大约95%的比例CIs的真正价值(基于参考方法)包括(理想情况下,覆盖率是95%)。
* Missingness的d二聚体水平与小腿周长的差异和深静脉血栓形成的诊断。
示例2:随机试验
一项随机试验比较集约管理的有效性(干预)和标准管理的严重精神疾病患者的社区。20.对于这个示例,我们视为衡量精神病理结果,综合精神病态的评定量表得分,并使用595分数观察患者在基线和两年的随访。我们估计的影响干预的分数在两年的后续调整基准分数,使用线性回归模型。
Missingness协变量的创建基线得分,在25%的失踪完全随机随机抽样研究的人口。这反映了想法,missingness在随机试验中可能会平衡在治疗组。另外,患者更严重的情况是创建精神病理学(得分高于中位数)的两倍是不一致的,因此有一个丢失的分数比患者基线温和精神病理学(数据缺失不是随机)。过程之前,除了归罪模型是一个线性回归基准分数的两年随访得分和随机的组。
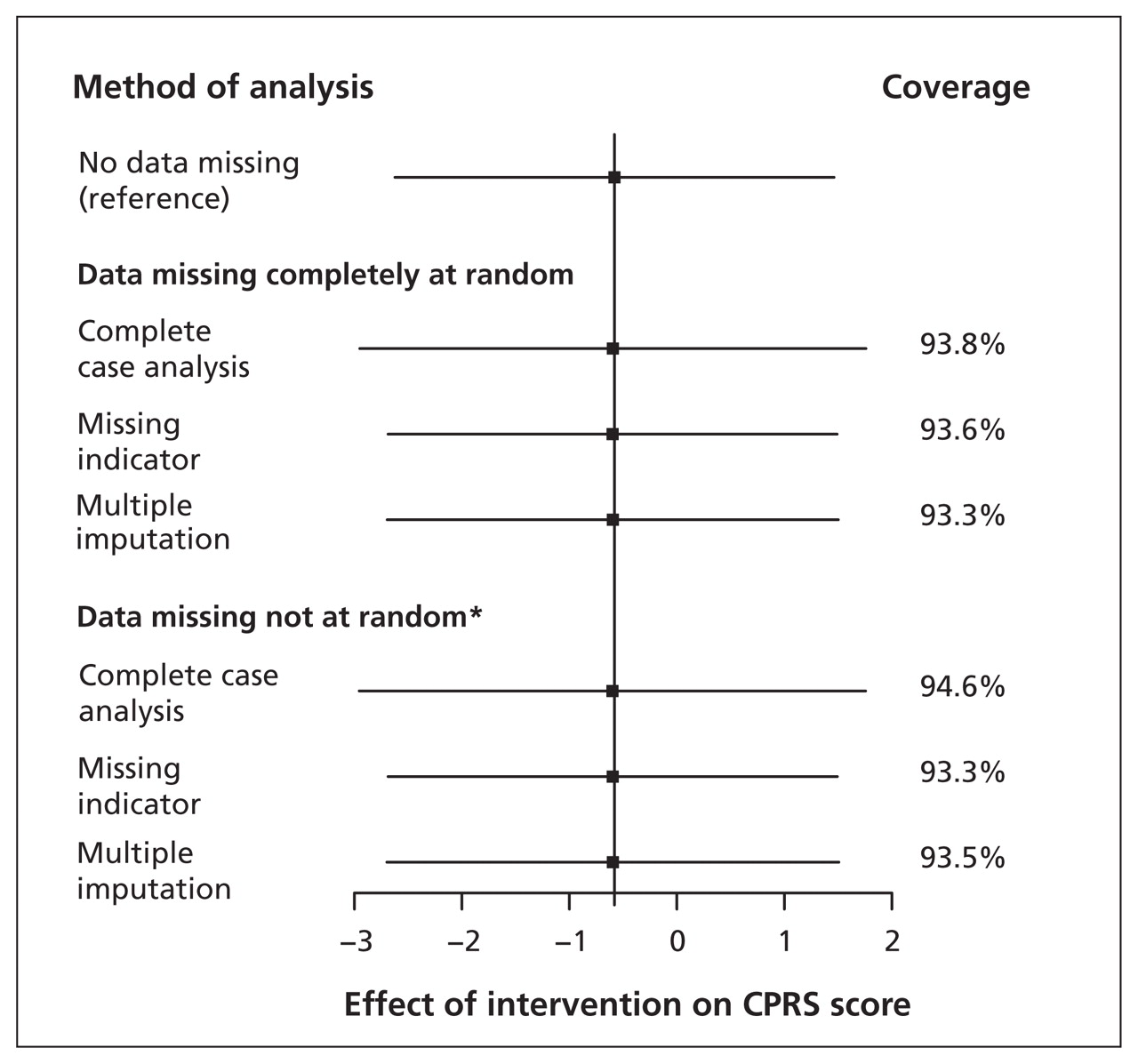
结果所示图2。数据缺失的完全随机和失踪不是随机的,所有的方法,包括missing-indicator方法,产生了正确的效应估计和合理的覆盖。然而,置信区间为完整的案例分析,反映其损失的统计力量。同样,不同方法之间的差异的比例增加而增加missingness(结果未显示)。

比较的方法(完整的案例分析,缺少指标,多个归责)来处理缺失数据在随机试验中对干预的效果全面精神病态的评定量表(碳污染减排方案)得分缺失的数据在一个基线变量。
注:估计效果和95%的置信区间(CIs)平均超过1000模拟,除了参考方法,分析引起完全观测数据集。报道表明大约95%的比例CIs的真正价值(基于参考方法)包括(理想情况下,覆盖率是95%)。
* Missingness基线变量与基线变量本身的值。
结论
正如先前所显示的,完整的案例分析不是一个有效的方法来处理缺失数据在非随机研究随机如果数据丢失。3在这种情况下,多个归责是推荐的选择。2虽然容易实现,但missing-indicator方法通常会导致偏见的估计在非随机研究(包括随机当数据丢失或失踪完全随机)。在随机试验中,missing-indicator方法是一个有效的方法来处理丢失的基线协变量数据,无论missingness机制。即使missingness在基线的比例很低,反是一个完整的案例分析不遵守当协变量调整意向处理原则。意向性治疗分析也可以由简单的省略不完整基线协变量的模型,但这可能会引出估计不太精确。missing-indicator方法遵守意向处理原则的重要优势。虽然missing-indicator方法最初提出了缺失数据“在病因学的研究中,应该限制其使用的随机试验。
要点missing-indicator方法是一个受欢迎的和简单的方法来处理缺失数据在临床研究,但一直在批评引入偏见。
在非随机研究中,所研究的因素或测试通常是相关的变量用缺失值,在这种情况下,missing-indicator方法通常会导致偏见的估计。
在随机试验中,基线与反是缺失值的分布可能是平衡在治疗组,这意味着missing-indicator方法将无偏估计和遵守意向处理原则。
脚注
利益冲突:没有宣布Rolf得出Groenwold伊恩·r·白,a . Rogier t . Donders。道格拉斯·g·奥特曼支持由英国癌症研究中心资助(C5529)。詹姆斯·r·卡彭特宣称他或他的机构已经收到资金从经济和社会研究委员会和医学研究委员会(MRC)缺失的数据研究,诺华公司为统计咨询公司和葛兰素史克公司,辉瑞和勃林格殷格翰集团领导课程缺失的数据。卡雷尔通用卫星支持荷兰科学研究组织(赠款917.46.360和918.10.615)。
这篇文章已经被同行评议。
这是一分之一偶尔系列检查有争议的方面的研究方法和报告。
参与者:所有作者贡献的概念和设计。Rolf得出Groenwold伊恩·r·白a Rogier t Donders和卡雷尔通用卫星写论文的初稿,詹姆斯·r·卡彭特和道格拉斯·g·奥特曼批判性的回顾。所有作者论文的修改。罗尔夫得出Groenwold,伊恩·r·怀特和卡雷尔通用卫星将作为担保人。
引用







{kind=link}
{kind=link}
{kind=link}
{kind=link}
相关文章
被……
-
循环肿瘤DNA分析通知辅助化疗在II期结肠癌(动态试验):统计分析计划
-
腹泻和抗生素暴露在提前进气COVID-19: 1153名住院患者的回顾性队列研究
-
预测的严重COVID-19基于注册瑞典的慢性阻塞性肺病(COPD)患者
-
减少青少年自残。个体参与者数据荟萃分析(RISA-IPD):系统回顾协议
-
早产儿预后模型预测死亡率:系统回顾和荟萃分析
-
Post-covid综合症在个人住院covid-19:回顾性队列研究
-
2型糖尿病和COVID-19-Related死亡率的关键护理:国家队列研究在英国,March-July 2020
-
MRI对早产儿的影响和他们的家庭:一个随机试验与嵌套的诊断和经济评价
-
开发和验证的临床死亡率预测模型,功能结果和卒中后认知障碍:一项研究协议
-
蜜罐随机对照试验统计分析计划
这个TOC的部分
类似的文章
