预后和预后研究:开发一个预后模型
BMJ2009年;338年doi:https://doi.org/10.1136/bmj.b604(2009年3月31日发布)引用这个:BMJ2009;338:b604
- 函授:P罗伊斯顿公关在{}ctu.mrc.ac.uk
- 接受2008年10月6日
在本系列的第一篇文章综述了为什么预后是很重要的,以及它是如何面对不同的医疗设置。1我们也强调了多变量模型用于病原学的研究和预后研究和概述了设计中使用的那些特点研究发展预后模型。在本文中,我们专注于开发一个多变量预测模型。我们说明了统计问题使用逻辑回归模型来预测一个特定的事件的风险。原则主要适用于所有多元回归方法,包括连续模型的结果和时间事件的结果。
总结分
模型与多个变量可以开发给准确识别预测
在临床实践中简单模型是可行的
没有共识的理想方法,开发一个模型
方法开发简单,可说明的模型是描述和比较
我们的目标是建立一个准确、歧视来自多个变量的预测模型。预测的模型可能是一个复杂的函数,在天气预报,但在临床应用的考虑实用性和表面有效性通常显示一个简单的,可说明的模型(如箱1)。
箱1个预后模型的例子
风险评分从逻辑回归模型预测的风险,术后恶心和呕吐(PONV)后第一个24小时内手术2:
风险评分=−2.28 +(1.27×女性性)+ (0.65×PONV的历史或晕车)+(0.72×非吸烟区)+(0.78×术后阿片类药物使用)
所有变量编码0(无或1对。
−2.28的值称为拦截和其他数字是估计回归系数的预测,表明他们相互调整的相对贡献的结果的风险。回归系数是日志(优势比)的变化一个单位在相应的预测。
PONV的预测风险(或概率)= 1 / (1 + e−风险评分)。
令人惊讶的是,没有普遍同意的方法建立一个多变量预测模型从一组候选预测。Katz读介绍了多变量模型,3和技术细节也广泛使用。456我们集中在几个相当标准的建模方法并考虑如何处理连续的预测因素,如年龄。
预赛
我们假设这里的可用数据是足够精确的预测和充分代表感兴趣的人群。在开始开发一个多变量预测模型之前,必须做出许多决策影响的模型,因此研究的结论。这些包括:
选择临床相关的候选预测可能包含在模型中
评估数据的质量和判断如何处理缺失值
数据处理的决定
选择的策略选择的重要变量最终的模型
决定如何连续变量模型
选择测量(s)模型的性能5或预测精度。
其他考虑因素包括评估模型的鲁棒性,有影响力的观察和离群值,研究可能的预测因素之间的相互作用,决定是否以及如何调整过度学习的最终模型(所谓的收缩),5和探索稳定(再现性)的一个模型。7
选择候选预测
研究经常测量比理智可以用于预测一个模型,和修剪是必需的。预测已经报告为预后通常会候选人。与他人高度相关的预测贡献小的独立信息和事先可能被排除在外。5然而,预测不重要在单变量分析中不应被排除在外的候选人。8910
评估数据质量
没有安全规则评估数据的质量。判断是必需的。原则上,数据用于开发预测模型应该适用。测量候选人预测和结果应该类似在临床医生或研究中心。预测已知相当大的测量误差可能是不合适的,因为这稀释他们的预后信息。
现代统计技术(如多重填补方式)可以处理缺失值的数据集。1112然而,所有方法做出重要但本质上不可测试的假设是如何失踪的数据。可能影响结果与缺失的数据量增加。缺失的数据很少是完全随机的。他们通常是相关的,直接或间接地与其他学科或疾病特点,包括研究下的结果。因此排除所有个体缺失值不仅导致损失的统计力量但经常错误的估计模型的预测能力和具体的预测。11一个完整的案例分析,这些做法也许是明智的,当一些观测(< 5%)失踪。5如果一个候选人预测有很多缺失的数据可能被排除在外,因为问题可能会复发。
数据处理的决定
通常,需要创建新变量(例如,舒张压和收缩压可能给平均动脉压)相结合。对于有序分类变量,如疾病的阶段,崩溃的类别或可能需要一个明智的选择的编码。我们反对将连续预测转化为二分法。13保持连续变量更可取,因为更多的预测信息保留。1415
选择变量
不存在共识的最佳方法选择变量。主要有两种策略,每一个变体。
在完整的模型方法的所有候选人变量包括在模型中。这个模型是声称避免过度拟合和选择性偏差,并提供正确的标准误差和P值。5然而,正如许多重要的初步选择必须包括所有候选人通常是不切实际的,完整的模型并不总是很容易定义。
落后的消除方法从所有候选人变量开始。一个名义上的显著性水平,通常5%,提前选择。一系列的假设测试应用于确定一个给定的变量应该从模型中删除。向前向后消除比选择(即从最佳人选预测模型建立)。16显著性水平的选择主要影响变量选择的数量。1%的水平几乎总是导致模型与变量少于5%的水平。重要性水平的10%或15%会导致包含一些不重要的变量,可以完整的模型方法。(一个变体是Akaike信息标准,17衡量模型适合对大型模型,包括一个点球,因此试图减少过度拟合。对于一个预测,则相当于选择15.7%的意义。17)
选择测试预测的意义,特别是在传统意义的水平,产生选择性偏差和乐观被称为过度拟合的结果,也就是说,模型(太)密切适应数据。5917选择偏见意味着回归系数是高估了,因为相应的预测更可能是重要的,如果其估计效果比较大(也许偶然)而不是更小。过度拟合导致更糟糕的是在独立的数据预测;它更可能发生在较小的数据集或弱的预测变量。但是请注意,选择预测变量与很小的P值(< 0.001)更容易选择偏差和过度拟合比弱预测P值附近的名义上的显著性水平。通常,预后数据集包括一些强有力的预测和几个较弱的。
模拟连续预测
处理连续预测多变量模型是很重要的。是不明智的线性假设,因为它可能导致误解的影响预测和准确预测新病人。14见箱2进一步评论如何处理连续预测预后模型。
2盒造型连续的预测因子
简单的用来检测和预测转换模型非线性可以系统地识别使用,例如,分段多项式,概括传统多项式(线性、二次等)。627权力转换的预测除了广场和多维数据集,包括倒数对数和根是允许的。这些转换包含一个词,但增强的灵活性可以扩展到两个词模型(例如,在日志中x和x2)。分段多项式函数可以成功预后研究发现模型非线性关系。多变量的分段多项式程序扩展到多变量模型包括至少一个连续的预测,427结合逆向消除较弱的预测和变换的连续的预测因子。
限制三次样条函数是一个替代方法模拟连续的预测因子。5他们的主要优势是其灵活性也许代表广泛的复杂曲线的形状。缺点是摆动的频繁发生在拟合曲线可能不真实和开放的误解2829日并没有一个简单的拟合曲线的描述。
评估性能
逻辑回归模型的性能可能是评估校准和歧视。校准可以通过策划调查事件的观察比例对预测风险组定义为个体预测风险的范围;一个常见的方法是使用10组同等大小的风险。理想情况下,如果观察到的事件和概率预测的比例同意在整个范围的概率,情节展示了45°线(即斜率为1)。这个情节可以伴随着Hosmer-Lemeshow测试,19虽然测试评估贫困校准的能力都是有限的。整体观察和预测事件概率是根据定义等于样本用于开发模型。这不是保证模型的性能评估时在不同样本的验证研究。我们将在下一篇文章中讨论,18更难得到模型执行在一个独立的样品比开发样品。
各种统计总结个人之间的歧视和没有结果的事件。接受者操作曲线下的面积,1020.或同等c(和谐)指数,是机会,鉴于两个病人,一个人将开发一个事件和其他谁不会,该模型将分配一个高概率事件前。的c指数预测模型一般为0.6和0.85(高值出现在诊断设置21)。另一个措施是R2,逻辑回归评估解释风险的变化,观察到的结果之间的相关性的平方(0或1),预测的风险。22
与肾癌预后生存模型的例子
在1992年至1997年之间,350例转移性肾癌患者进入一个随机试验比较干扰素和醋酸甲羟孕酮在31个中心在英国。23我们开发一个预后模型(二进制)死亡的结果在第一年和存活12个月或者更多。347患者随访信息,218(63%)在第一年就去世了。
我们采取以下初步决定之前建立模型:
我们选择了14个候选人预测,包括治疗,据报道预后
四个预测10%以上缺失的数据被消除。表1⇓显示了10剩余候选预测变量(11)。
性能状态(0,1,2)被建模为一个单一的实体与两个虚拟变量
说明,我们选择使用落后的重要预测因子模型消除Akaike信息标准17和使用0.05的显著性水平。我们比较结果与完整模型(所有10个预测)
因为它的偏斜分布,时间转移转化为近似通过添加1天,并对数常态。所有其他的连续预测最初描述为线性的
对于每一个模型,我们计算了c指数和接收机操作曲线和校准使用Hosmer-Lemeshow测试评估。
表1⇑显示了完整的模型,两模型选择减少了反向淘汰使用Akaike信息标准和5%的意义。积极的回归系数表明增加死亡的风险超过12个月。所有的三个模型失败Hosmer-Lemeshow拟合优度试验(P > 0.4)。
两个重要的点出现。首先,更大的意义给模型与更多的预测水平。其次,减少模型的大小通过减少显著性水平几乎没有影响c索引。图1⇓显示了类似的接收机操作曲线的三种模式。然而,我们注意到,c指数一直在批评其无法检测到有意义的差异。24正如经常发生的一样,一些预测是强烈影响,其余是相对较弱。删除较弱的预测几乎没有影响c索引。

图1接受者操作特征(ROC)曲线三种多变量模型与肾癌的生存。
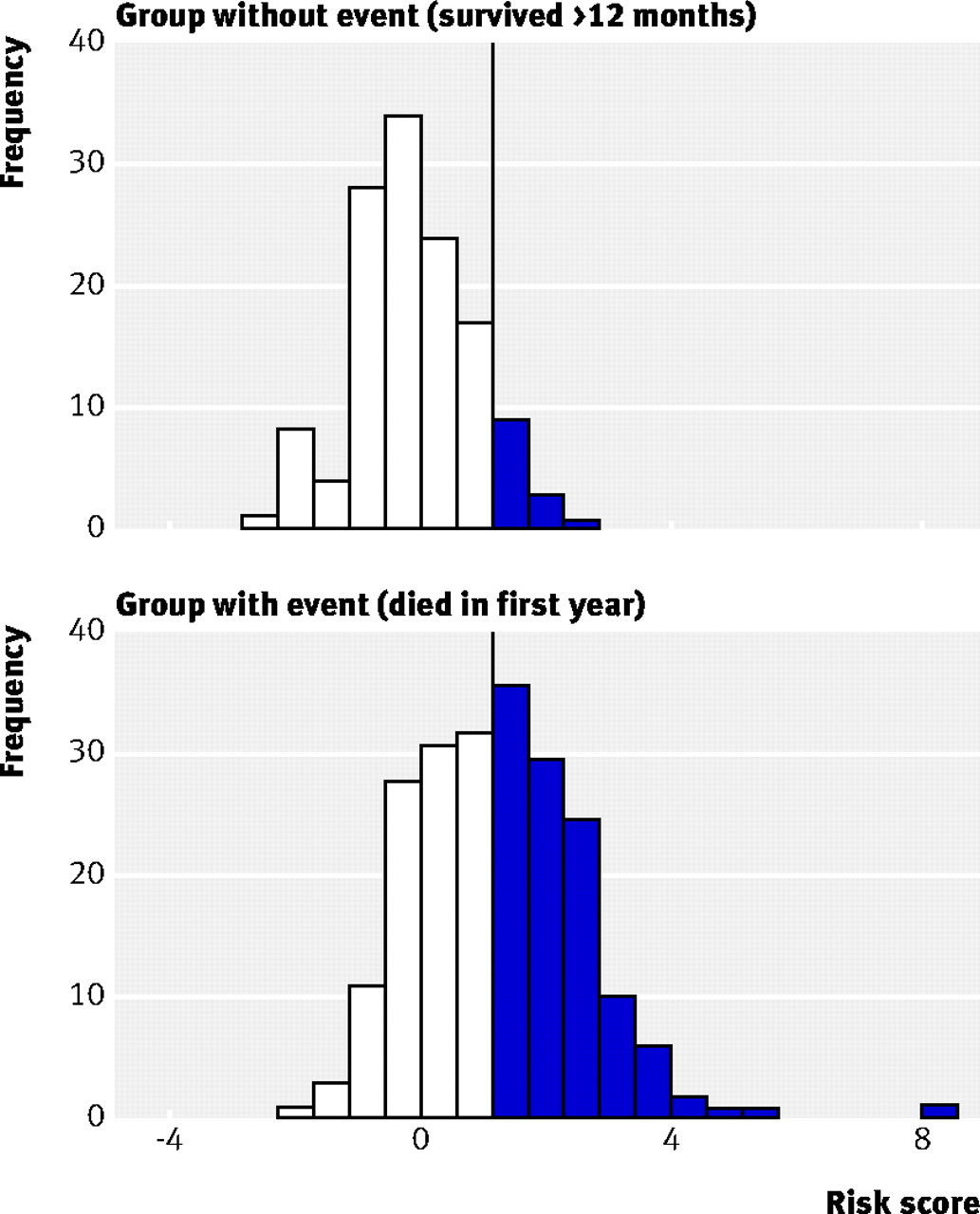
预后模型的一个重要目标是将患者分为风险组。作为一个例子,我们可以使用作为一个截止值与完整模型风险评分为1.4(垂直线,图2所示⇓),对应于80%的预测风险。估计患者的风险高于截止值预计将在12个月内死亡,和那些风险低于截止存活12个月。结果假阳性率是10%(特异性90%)和真正的(灵敏度)积极的利率是46%。虚假和真实的结合正利率接收机操作曲线(图1所示⇑)和更多的间接风险得分的分布在图2中⇓。重叠的风险分数之间那些死亡或存活12个月是相当大的,表明的解释c指数为0.8(表1⇑)却并非易事。24

连续预测接下来处理多变量是分式多项式程序(见框2)使用反向淘汰5%的显著性水平。只有一个(血红蛋白)显示显著的非线性连续预测和变换1 /血红蛋白2是表示。该变量被选在最后的模型和白细胞计数(表2中就被淘汰了⇓)。
图3⇓显示了血红蛋白浓度和12个月死亡率之间的联系,当血红蛋白以不同的方式包括在模型中。模型与血红蛋白10组分类变量,虽然吵闹,达成更好的与模型包括分段多项式形式的血红蛋白比其他模型。低血红蛋白浓度似乎比线性函数表示的更危险。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
在这个例子中,模型根据造型多样选择的细节,但表现不同的造型方法非常相似。尽管血红蛋白之间的关系描述的分段多项式模型和12个月的死亡率比线性函数,歧视的获得是有限的。这可能是解释为少数患者血红蛋白浓度较低。
讨论
我们已经介绍了几个重要的方面发展与经验数据的多变量预测模型。虽然没有明确的共识模型构建,最好的方法的重要性有足够的样本容量和高质量的数据是广泛的同意。模型构建从较小的数据集需要特别小心。5910模型的性能可能高估了开发和评估时在同一数据集。最大问题是小样本大小,许多候选预测因子,弱影响力的预测因子。5910乐观的数量模型中可以通过内部评估和纠正验证技术。5
开发一个模型是一个复杂的过程,所以报告的读者一个新的预后模型需要知道足够的细节数据处理和建模方法。25所有候选预测和那些包含在最终的模型及其显式编码应该仔细报道。所有的回归系数都应该报告(包括拦截),允许读者来计算风险预测自己的病人。
模型的预测性能和准确性可能受贫穷的方法论选择负面影响或弱点的数据。但即使是一个高质量的模型,可能只是太多无法解释的变异生成准确的预测。多变量模型的关键需求因此可移植性,或外部有效性,证实该模型在新但类似患者按预期执行。26我们认为这些问题在接下来的本系列的两篇文章。1821
笔记
引用这个:BMJ2009;338:b604。
脚注
本文是第二个在一系列的四个旨在提供一个可访问的预后研究的原则和方法的概述
资金:公关支持由英国医学研究理事会(U1228.06.001.00002.01)。KGMM和青年志愿服务由荷兰科学研究组织(ZON-MW 917.46.360)。DGA由英国癌症研究中心的支持。
贡献者:本系列的四篇文章被DGA的构思和计划,KGMM,公关,青年志愿。公关写这篇文章的初稿。所有作者导致后续修订。公关是担保人。
利益冲突:没有宣布。